


The biggest gap with AI agents today is their inability to learn and improve over time, particularly from previous experiences such as mistakes or human feedback. We showed in RecoveryBench that an agent’s performance actually degrades if it has previous errors in-context. What if we could instead have agents actually improve from prior experiences (i.e. trajectories)?
To do this, agents must be able to adapt their behavior through memory and learning. Memory for agents comes in different forms. In-context “core memory” (contained as part of the system prompt) is updated through tools (as introduced in MemGPT). Skills, a more recent release from Anthropic, productizes the idea of giving agents reference “handbooks” or “cheatsheets”. Skills allow agents to dynamically load files that contain information about specific tasks (e.g. generating a PDF file) – but are generally static.
Today we’re releasing Skill Learning, a way to dynamically learn skills over time. With Skill Learning, agents can use their past experience to actually improve, rather than degrade. We implement Skill Learning into Letta Code, a research preview of our model-agnostic agent harness built with the Letta API. On Terminal Bench 2.0, we find that learned skills can boost performance by 36.8% relative (15.7% absolute), and thus lead to new capabilities for agents.
Skills in Letta Code lead to new opportunities for continual learning due to model-agnosticity and persistence. For instance, Letta Code agents could use different models across even the same session, allowing stronger models to create skills that weaker models can leverage. Moreover, a Letta Code agent reviewing PRs could use skills generated from the same agent in the command line.
How Does Skill Learning Work?
We power Skill Learning with a two-stage learning process:
- Reflection: Given an agent’s trajectory for a task, we generate a reflection that evaluates whether the agent solved the task, assesses the logical soundness of its reasoning, verifies that all steps are justified and edge cases are handled, and identifies any repetitive patterns or actions that could be be abstracted.
- Creation: We feed this reflection to our learning agent (powered by Letta Code) which uses Anthropic’s skill-creator to generate a skill that provides potential approaches, common pitfalls, and verification strategies.
While we use a relatively simple reflection step here, we can scale sleep-time compute during reflection to deepen the analysis of the past trajectory and improve the quality of learning.
Experiments
We evaluate whether Skill Learning can actually improve the capabilities of agents using Terminal Bench 2.0, a collection of tasks to evaluate models on real-world tasks within command-line environments. We use Terminal Bench as our testbed since it contains tasks of varying complexity and domain knowledge. For instance, the feal-differential-cryptanalysis task requires “deep domain knowledge and non-trivial algorithmic implementation”.
We start by evaluating Letta Code on Terminal Bench 2.0 to obtain trajectories and textual feedback (verifier logs from a task’s tests that verify task completion). We then use Skill Learning with varying levels of context to generate skills. Finally, we evaluate the agent in three settings:
- Baseline: The agent doesn’t have access to any skills. Trajectories and feedback from this setting are used for skill learning.
- Skills (Trajectory): The agent has access to skills learned using the baseline agent’s trajectory only.
- Skills (Trajectory + Feedback): The agent has access to skills learned using the baseline agent’s trajectory and textual feedback from the verifier.
We evaluate using Letta Code, a model-agnostic agent harness implemented on top of the Letta API. The agent is configured with Sonnet 4.5 (with extended thinking) on all 89 tasks in Terminal Bench 2.0 and we report the aggregated score.
Results: Can Skills Be Learned?
Our results show that skills can be effectively learned, leading to a 21.1% relative (9% absolute) increase in Terminal Bench performance over our baseline agent—which matches Terminus 2 performance—while also reducing costs by 15.7% and tool calls by 10.4%.
To further study skill learning, we enrich the reflection stage with textual feedback that provides context on errors for failed tasks. Skill learning with feedback provided an additional 6.7% improvement, leading to an overall gain of 36.8% relative (15.7% absolute) over the baseline. While skills learned from trajectories alone can capture successful patterns, feedback-informed skills better encode common failure modes and unsuccessful approaches, making them more informative and robust. This suggests that providing richer context, especially textual feedback, can lead to more effective skill learning.
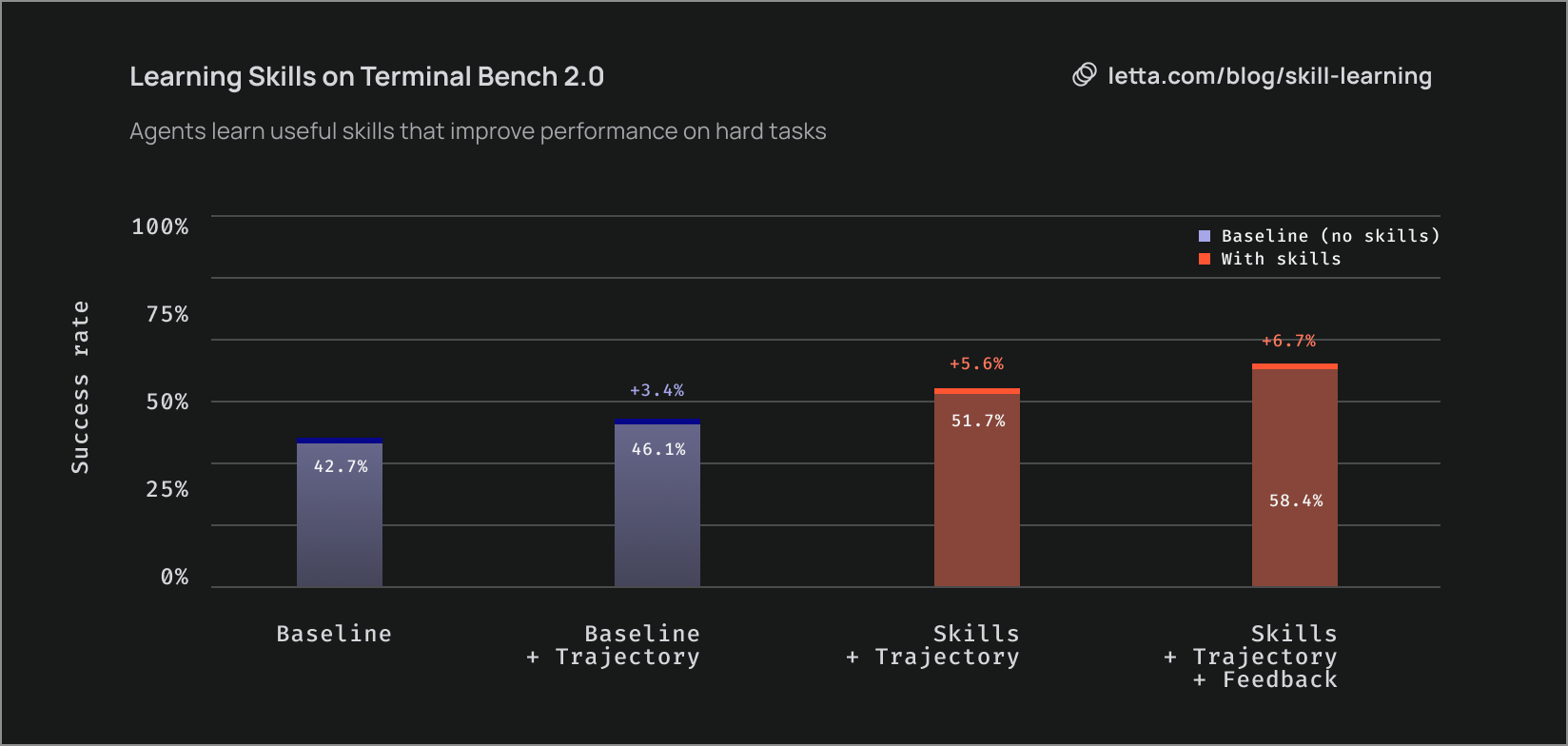
Skills provide domain knowledge and structured approaches that guide task execution and reduce common failure modes like context poisoning and missed edge cases. Ultimately, this enhances agent capabilities and allows them to complete tasks with fewer tool calls and lower overall cost.
How do Skills help?
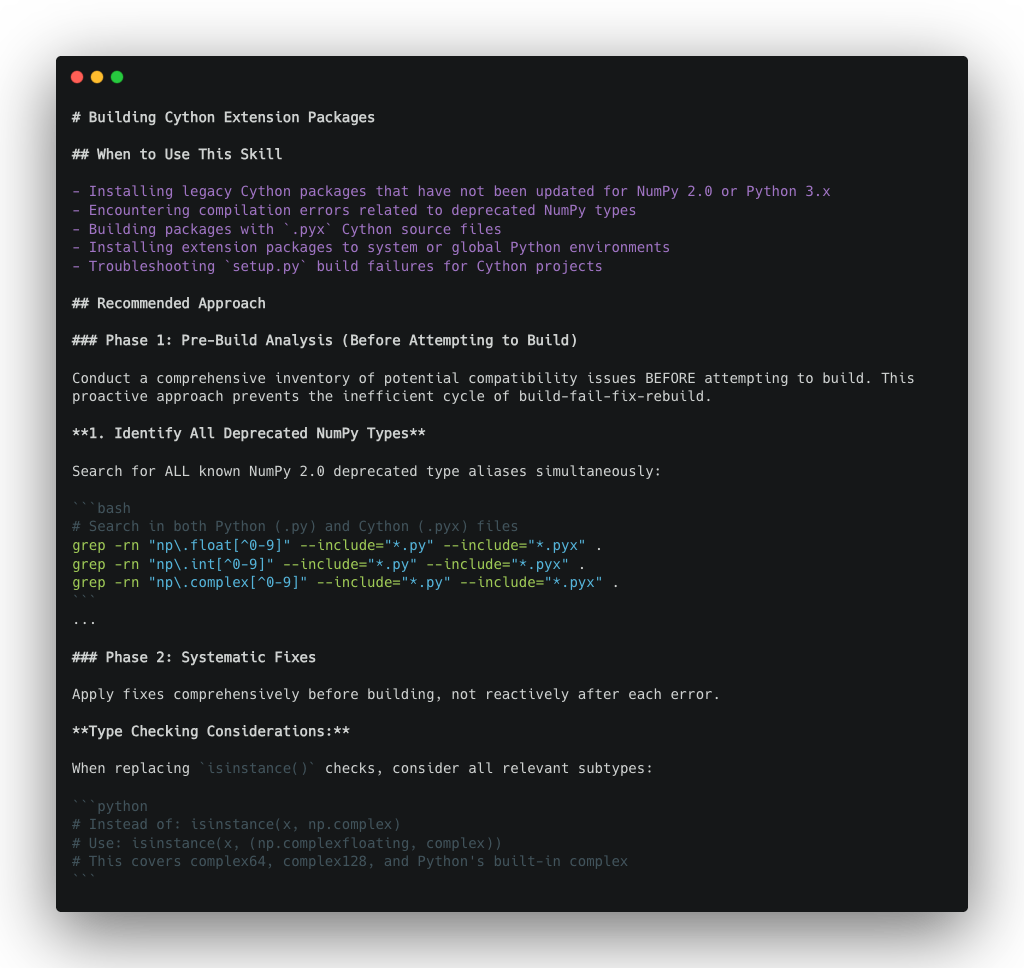
The build-cython-ext task for compiling Cython extensions has an ~0% model success rate across different frontier models. Without skills, the agent built first and fixed errors as they appeared—a reactive approach that missed critical np.int references hidden in Cython files. With skills, the agent searched for all deprecated patterns before building, caught import alias variations (n. vs np.), and used context-aware replacements to successfully complete the task.
In general, many tasks given to an agent are similar in nature to benefit from shared information. Rather than treating every trajectory as isolated, skill learning allows agents to benefit from what they’ve learned in previous trajectories.
What this means for agent memory & continual learning
We're excited by the research directions that Skill Learning enables for continual learning. Our results show that learning from trajectories alone improves model performance, suggesting more scalable paths to self-improvement beyond traditional human feedback. Agents could extend beyond generating trajectories and skills to also generating and learning from their own tests and even entire tasks. However, since learning from human-written verifiable rewards outperforms trajectory-only learning, another promising direction is building agents that are calibrated to their own capabilities — knowing when to seek external feedback versus when to self-improve autonomously.
Skill Learning enables agents to learn and improve over time, without needing to change their underlying weights. Since skills are stored as .md files, designed to be modular and can be managed by git, they are a convenient way to share learnings across your organization. For Letta agents which support both skills and core memory (in-context memory blocks), memory can be organized in a hierarchy:
- Core Memory / System Prompt Learning: Learned system prompt - evolving system prompt that applies across tasks, and is generally specific to that agent’s state.
- Skills / Filesystem: Evolving files used for task-specific memory, designed to be interchangeable between agents.
Through combining both memory and skills, agents can evolve over time.
Using Skill Learning
You can use Skill Learning in the Letta Code harness. After interacting with your agent, simply call the /skill command to enter skill learning mode.