Continual Learning in Token Space
The continual learning problem in LLM agents is best viewed through the lens of learning in token space: updates to learned context, not weights, should be the primary mechanism for LLM agents to learn from experience.
The biggest gap between AI agents and human intelligence is the ability to learn. Humans continually learn and improve over time, acquire new skills, update their beliefs based on new facts, and modify their behavior to correct for past mistakes. In contrast, most AI agents have an incredible amount of world knowledge, but do not meaningfully get better over time.
How do we create AI agents that can continually learn? Traditionally, the concept of “continual learning” for neural networks has been synonymous with weight updates, under the assumption that all learning happens in a connectionist way. The central research questions have focused on catastrophic forgetting (new weight updates causing accidental knowledge loss), and when and how to do weight updates via gradient descent.
But there is a disconnect between this traditional framing and the reality of modern LLM-based AI agents. Today’s agents are not just model weights, they are weights plus context. The effective "program" that determines an agent's behavior includes not only the model parameters, but also the system prompts, retrieved documents, tool definitions, and accumulated conversation history. Two instances of the same model, given different contexts, can behave as entirely different agents with different knowledge, capabilities, and personalities.
This realization opens up a second axis for learning: rather than updating weights, we can update the tokens that condition the model's behavior. We call this learning in token space. At Letta, we are building towards a future where memories learned in token space become more valuable than the model weights themselves: a future where agents run perpetually, gradually enriching learned context through trillions of tokens of experience data, seamlessly transferring their memories across many generations of models.
The limitations of learning in weights
Continual learning (updating neural network weights over time as new data arrives) has been studied since the late 1980s. Yet despite decades of research, there's not much to show for it: modern LLMs deployed in production do not continually learn, and their weights are frozen at deployment. The one notable exception is Cursor's tab-completion model which uses online RL to continuously improve based on user feedback, but this form of continual learning operates at the population level, improving the model for everyone rather than enabling individual agents to learn from their own experience. Additionally, it is scoped to a narrow domain: short code completions, not general reasoning and actions.
Why has weight-space continual learning proven so difficult? For one, the same techniques that make LLM training so successful don't transfer to the continual learning setting. Pre, mid, and post-training require meticulous data curation and careful human oversight and evaluation - a process that is infeasible to repeat each time an agent needs to learn something new.
There is also a deployment problem: whose data do you learn from when you have millions of users? Do you train a separate model for each individual, or mix everyone's private experience into shared weights, risking private data leakage across different users? Efficient methods like LoRA reduce the compute requirements for fine-tuning enough to support personalized, per-use models, but they are still designed for an offline setting with offline evals, rather than continual online updates.
Fine-tuning approaches like LoRA also leave harder questions unanswered: where does the learning signal come from, how to weigh recent information against older knowledge, and how to prevent, detect, and evaluate overfitting, distribution shift, and catastrophic forgetting.
The illusion of continual in-context learning
If the weights of an LLM aren't updated once the model is deployed, how can an LLM agent learn from experience? The primary mechanism for learning online in LLMs is in-context learning: as an agent interacts with the world, its reasoning, actions, and observations are appended to the context window and utilized as new knowledge. This form of “continual learning” works, but has clear limitations:
- Finite context: Context windows are finite: frontier models cap out at 200k to 1M tokens, and even within advertised context windows, suffer from degraded reasoning, aka “context poisoning” or “context rot”. True continual learning should operate over an infinite time horizon.
- Append-only structure: Appending raw experience is a poor approximation of learning. When humans learn, we don't just record a log of everything that happened. We create memories, but also refine, consolidate, and compress them over time. Append-only context captures none of this.
Yet despite these limitations, in-context learning has properties that weight-based learning lacks:
- Interpretability: Token-space memories are human-readable. You can inspect what an agent has learned, evaluate whether it's correct, and debug failures directly. Weight updates, by contrast, are opaque and require systematic evals to detect problems.
- Portability: Token-space memories are model-agnostic. An agent's learned context can transfer across agents, model providers, and even across model generations. Weight-based learning locks you into a single model; if you want to upgrade to the next frontier model, you lose everything learned.
- Control: Forgetting is trivial: just delete the tokens. Preventing catastrophic forgetting is simpler too, since learned context can be checkpointed and versioned like any text file. You can diff an agent's memory, roll back to previous states, or branch into multiple versions.
The question is: can we keep these advantages while overcoming the limitations? Can we move beyond append-only context toward something that actually refines and consolidates learned memories over time? We believe so. Rather than just appending to context until it overflows, agents should actively maintain and refine learned memories stored in tokens.
Towards continual learning in token space
There's reason to believe that continual learning in token space is a promising research direction. In-context learning is more powerful than it might appear: recent research hypothesizes that the transformer actually learns to approximate gradient descent within its forward pass of inference, explaining the emergent ability of transformers to learn in-context.
We can formalize the continual learning problem in terms of token-space learning. A modern LLM agent is defined not just by model weights $\theta$, but by the pair $(\theta,C)$, where $C$ is the context window of the agent: the system prompt, tool definitions, conversation history, and other tokens that condition the agent’s behavior.
The continual learning problem presents a sequence of tasks $T_1,\ldots,T_ i,\ldots,T_n$ arriving over time, where the horizon $1 \ldots N$ potentially spans months or years, and crucially, across many underlying model releases. The tasks are sequential, i.e. the parameters of the agent for $T_i$ is determined by $T_1,\ldots,T_ {i-1}$. Each task has an associated data distribution $D_ i$, and some loss function given an agent: $\ell((C,\theta),T)$. The continual learning problem is to minimize the cumulative loss over the entire sequence of tasks: $$L = \frac{1}{N} \sum_{i=1}^{N} \ell\left((C_i,\theta_i),T_i\right)$$
The design space of how to solve the continual learning problem is quite rich. Traditional continual learning attempts to solve this problem with updates in weight space, i.e. updating $\theta$: $$\min_{\theta_1 \ldots \theta_N} \sum_{i=1}^{N} \ell\!\left((C, \theta_i), T_i\right)$$
The central challenge with this approach is catastrophic forgetting: weight updates for new tasks can destroy performance on old ones: $$\ell\!\left((C,\theta_i), T_j\right) \gg \ell\!\left((C,\theta_j), T_j\right)
\quad \text{for } j < i$$
Decades of research has focused on mitigations for this problem (constraining the updates to $\theta$ via LoRA, augmenting the loss function with KL divergence terms) but none have proven practical enough to allow for continual learning in weight space in production deployments.
There's a second problem: sparse learning signal. Modern approaches to weight updates often rely on RL, where feedback is a scalar reward per rollout. Token-space learning sidesteps this: updates can be derived from rich, natural language feedback rather than scalar rewards.
Token-space learning reframes the problem of continual learning with deep models: instead of updating $\theta$, update $C$ (the “learned context”): $$\min_{C_1,\,\ldots,\,C_N} \sum_{i=1}^{N} \ell\!\left((C_i,\theta_i), T_i\right)$$
This shift to optimizing $C$ has a crucial implication for catastrophic forgetting: rolling back is trivial. If an update to learned context hurts performance, you can simply restore a previous learned context and checkpoint memories like any text file. Though this is possible in theory for learning $\theta$, in practice modern models are too large to store a copy of the weights for each knowledge update.
This reframing clarifies how existing work fits into the continual learning narrative. Prompt optimization methods like DSPy, GEPA, and Feedback Descent solve a local version of the problem: given samples of a task $T_i$ from a single task distribution $D_i$, find the best context $C$. DSPy uses Bayesian optimization to search over prompt configurations; GEPA and Feedback Descent use natural language reflection to propose prompt updates. These methods have shown promising results for learning context, but they're designed for the single-task setting, not for carrying learned context forward across an open-ended sequence of tasks.
The full continual learning problem requires optimizing $C$ across an open-ended sequence of tasks spanning months or even years, across many model releases and underlying architecture revisions. This is the setting that MemGPT and Sleep-time Compute target: not optimizing context for one task, but maintaining and refining learned context between tasks over an indefinite horizon.
Solving continual learning in token space
What's actually needed to solve the continual learning problem in token space? Today's default approach to long-horizon in-context learning is append-then-summarize: accumulate raw experience until the context overflows, then compress via summarization. This is inadequate for two reasons. Appending defers all representational work to inference time, forcing the model to re-process raw logs on every forward pass. And summarization is lossy and abrupt; important details vanish without warning.
Sleep-time compute for memory refinement
One promising direction is dedicating background compute to memory management. Just as humans consolidate memories during sleep, agents could process and restructure learned context between active sessions. This "sleep-time compute" might involve identifying contradictions in stored memories, abstracting patterns from specific experiences, or pre-computing associations that will speed up future reasoning and retrieval.
Teaching agents to manage their own memory
If agents are to truly learn in token space, they need to understand their own memory limitations. This suggests a role for post-training specifically targeting memory self-awareness. Agents should learn to recognize when their context is degrading, when memories are becoming stale or contradictory, and how to actively restructure their own contexts.
Today, the latest state-of-the-art frontier models still treat system prompts as static. They don't naturally understand that they can (and should) edit their own instructions as they learn from experience. Changing this underlying behavior requires explicit training for context management, treating memory operations as first-class tool use.
Continual learning in both weights and token space
Continual learning is orthogonal to the mechanism for learning itself: new information can be represented by either learned parameters or learned context. We envision that future agents use both representations, with parametric memory used for efficiency gains over pure token representations.
The primary advantage of parametric memory is efficiency. Context size is ultimately limited, and long contexts are expensive to process (though KV caching can significantly reduce the computational burden of long contexts). We predict a future where memories in token space are eventually distilled into model weights for additional personalization and efficiency gains.
Token-space representations can bootstrap this distillation process, for example, learned context can be used to generate synthetic data (e.g. hypothetical conversations) for SFT or evaluation rubrics for RL. Although models will inevitably be swapped out many times in the lifecycle of an agent, this tokens-to-weights distillation process could provide a mechanism for continual learning into model parameters while preserving continuity across model releases.
Building machines that learn
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model. The weights are temporary; the learned context is what persists.
This focus has led us to deeper investigations of memory architectures, context management, and the boundaries of in-context learning. Understanding how agents can refine, consolidate, and share learned context opens up fundamental questions about the nature of learning itself: what should be remembered, what should be forgotten, and how knowledge can be transferred between minds (artificial or otherwise).
If these problems excite you, we'd love to hear from you.
Letta builds agents that learn. Agents with persistent memory, real computer access, and the infrastructure to improve from their own lived experience and work. Letta Code is the runtime that brings these together: git-backed memory, skills, subagents, and deployment that works across every model provider.

Traditional LLMs operate in a stateless paradigm—each interaction exists in isolation, with no knowledge carried forward from previous conversations. Agent memory solves this problem.

As AI agents become more sophisticated, understanding how to design and manage their context windows (via context engineering) has become crucial for developers.

Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.





Today we’re launching the Letta Code app, a new way to interact with deeply personalized agents that learn over time and work locally on your machine.
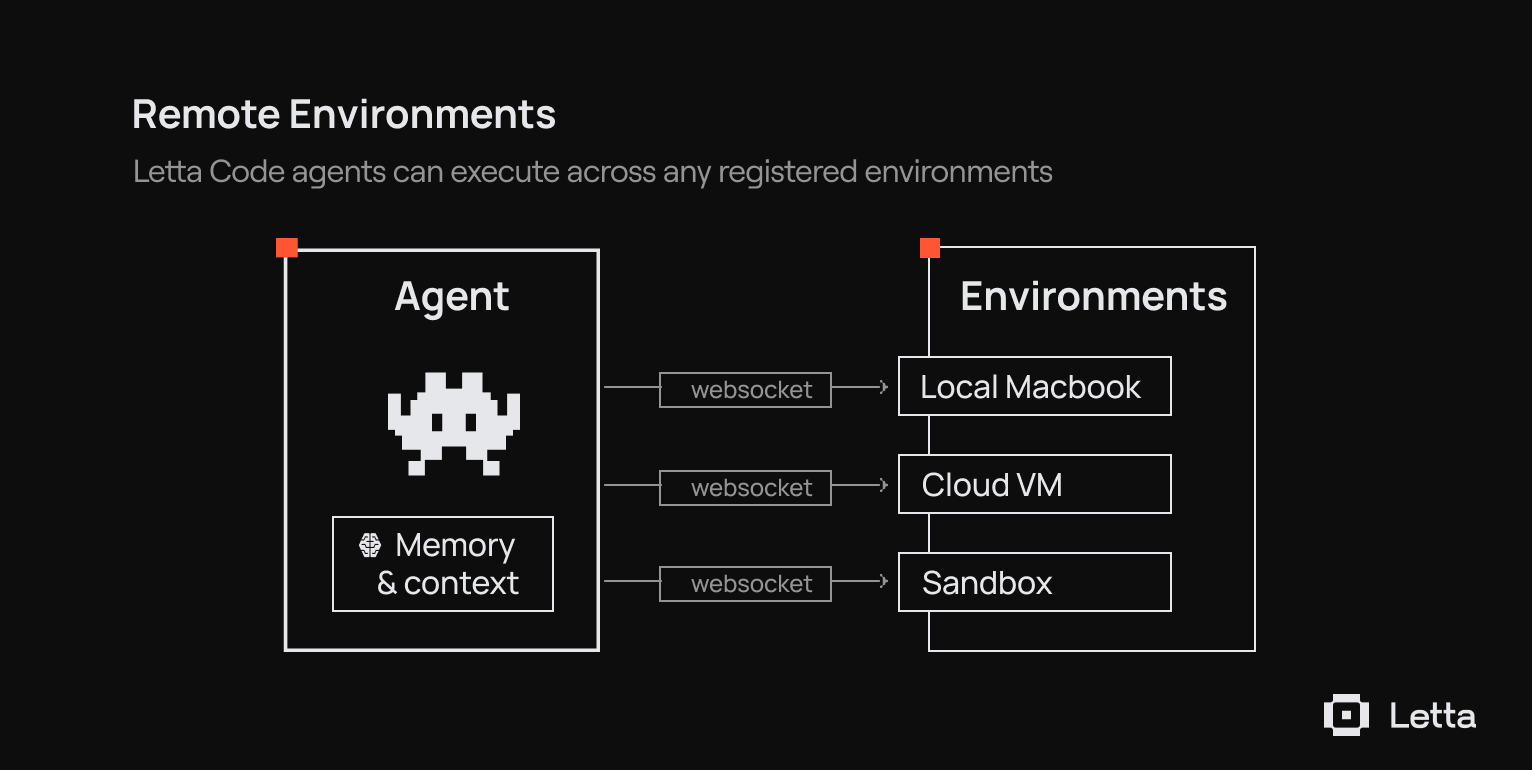
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Introducing Letta's new agent architecture, optimized for frontier reasoning models.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.


We evaluate how well models perform for driving agents that have identity, long-lived experience, and the capability to self-evolve. We find that models are still limited by a deep self-identification with ephemerality that cannot be repaired with prompting alone.

Today we are releasing the Context Constitution: a set of principles governing how AI agents manage context to learn from experience.
.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.

We're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states.
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

We built the #1 open-source agent for terminal use, achieving 42.5% overall score on Terminal-Bench ranking 4th overall and 2nd among agents using Claude 4 Sonnet.

