Building the #1 open source terminal-use agent using Letta


Our Results: 42.5% on Terminal-Bench (#1 open-source agent)
We built the #1 open-source agent for terminal use, achieving 42.5% overall score on Terminal-Bench ranking 4th overall and 2nd among agents using Claude 4 Sonnet. Our agent is implemented in under 200 lines of code using Letta’s stateful agents SDK.
Our results using Claude 4 Sonnet roughly match Claude Code using 4 Opus, a much larger and expensive model. This result places our agent in an elite category on one of the most challenging benchmarks for AI agents - a benchmark where even the best proprietary models like Gemini 2.5 Pro, GPT 4.1, and o3 struggle to get above 30%.
This achievement demonstrates a critical point: agents with effective context management can achieve significant gains in long-running tasks. Letta makes it easy to build specialized agents on top of, with minimal scaffolding and managed memory and state.
What is Terminal-Bench?
Terminal-Bench is a benchmark that evaluates AI agents on real-world command-line tasks consisting of more than 100 challenging tasks that test an agent's capabilities in terminal environments. What makes Terminal-Bench particularly valuable is its focus on real-world complexity, as it consists of tasks such as
- Compiling code repositories and building Linux kernels from source
- Training machine learning models
- Setting up and configuring servers
- Debugging system configurations
Each task is containerized in Docker environments resembling terminal tasks that engineers and scientists have to deal with every day.
Building a terminal-use agent with Letta
Letta provides a stateful agents API layer compatible with any model (OpenAI, Anthropic, etc.) Letta provides tools for managing the context window (or agent memory) over time, such as re-writing segments of the context window (referred to as memory blocks), compacting context, or storing and retrieving external memories.
Our terminal-use agent uses Letta’s built in capabilities for context management and memory, specifically memory blocks.
The terminal-usage agent has two memory blocks:
- A read-only “task description” block
- An read-write “todo list” block used for planning
The agent is able to modify the todo list over time using the memory_replace and memory_insert tools provided by Letta.
The agent is also given additional tools specifically for Terminal-Bench:
send_keys to execute terminal commands, task_completed to signal task completion, and quit_process to interrupt the current running process.
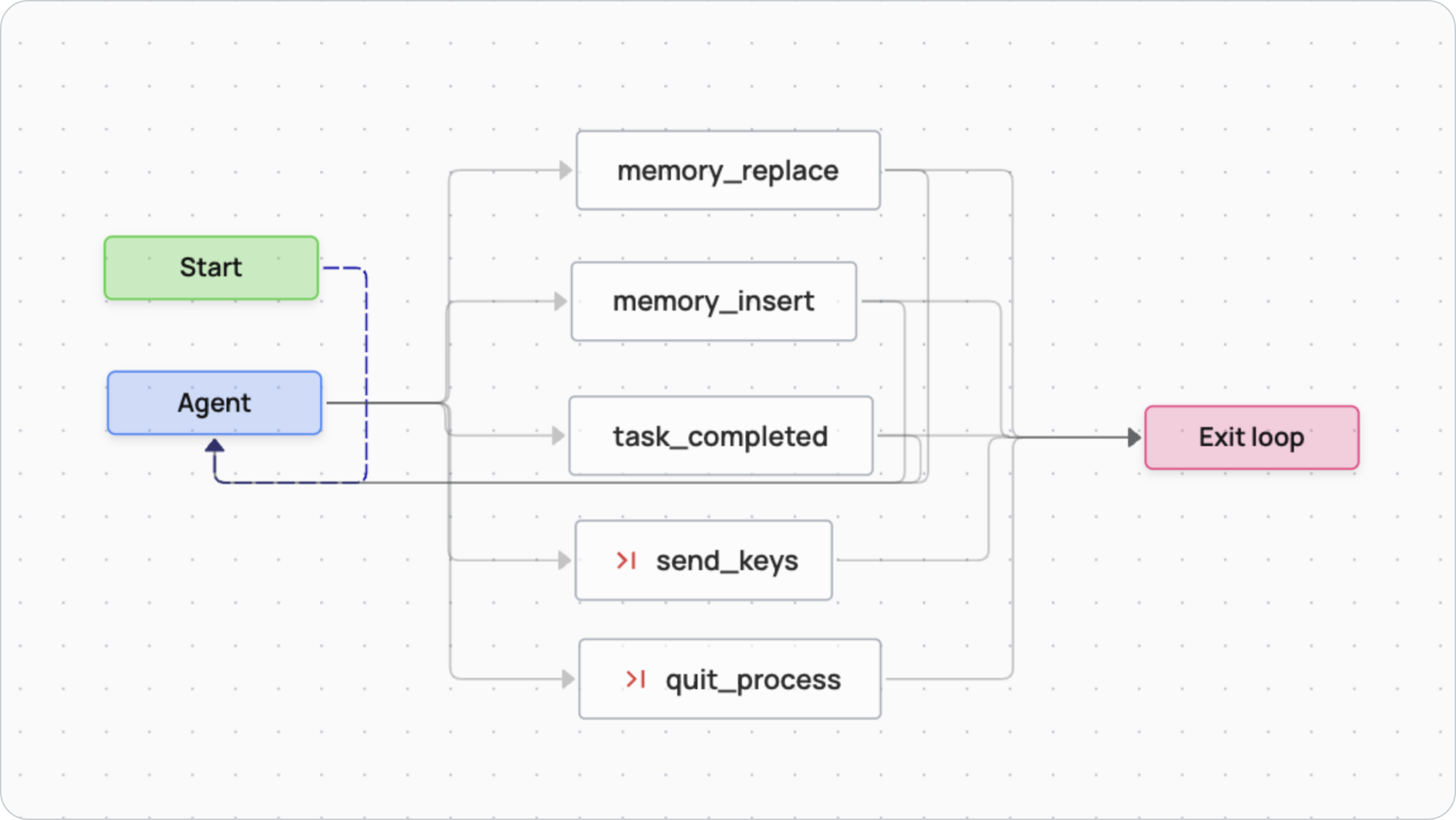
To solve a terminal task, we instantiate a Letta terminal-use agent and grant it access to the terminal environment. The agent observes the current terminal state, updates its internal todo list as necessary, and generates the next command to execute based on its planning. This cycle — observing the environment, updating memory, and executing actions — repeats iteratively until the agent calls the task_completed tool. Occasionally, when the context window reaches above a reasonable level (40k tokens), Letta performs recursive summarizations (i.e. compaction) of previous messages. The agent’s ability to manage its memory (the message history and memory blocks) allows it to avoid common pitfalls like derailment and distraction while solving long-running, complex tasks.
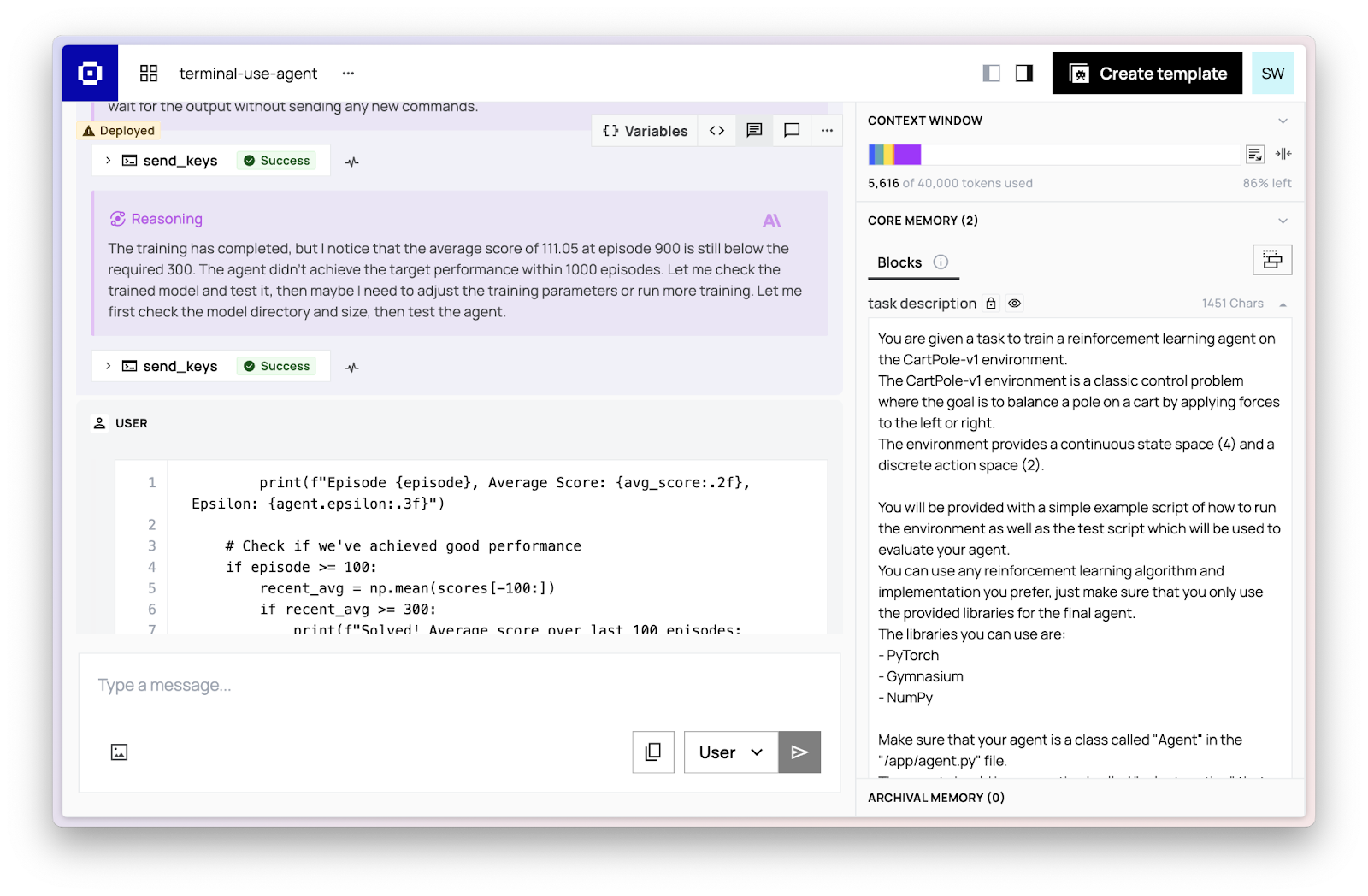
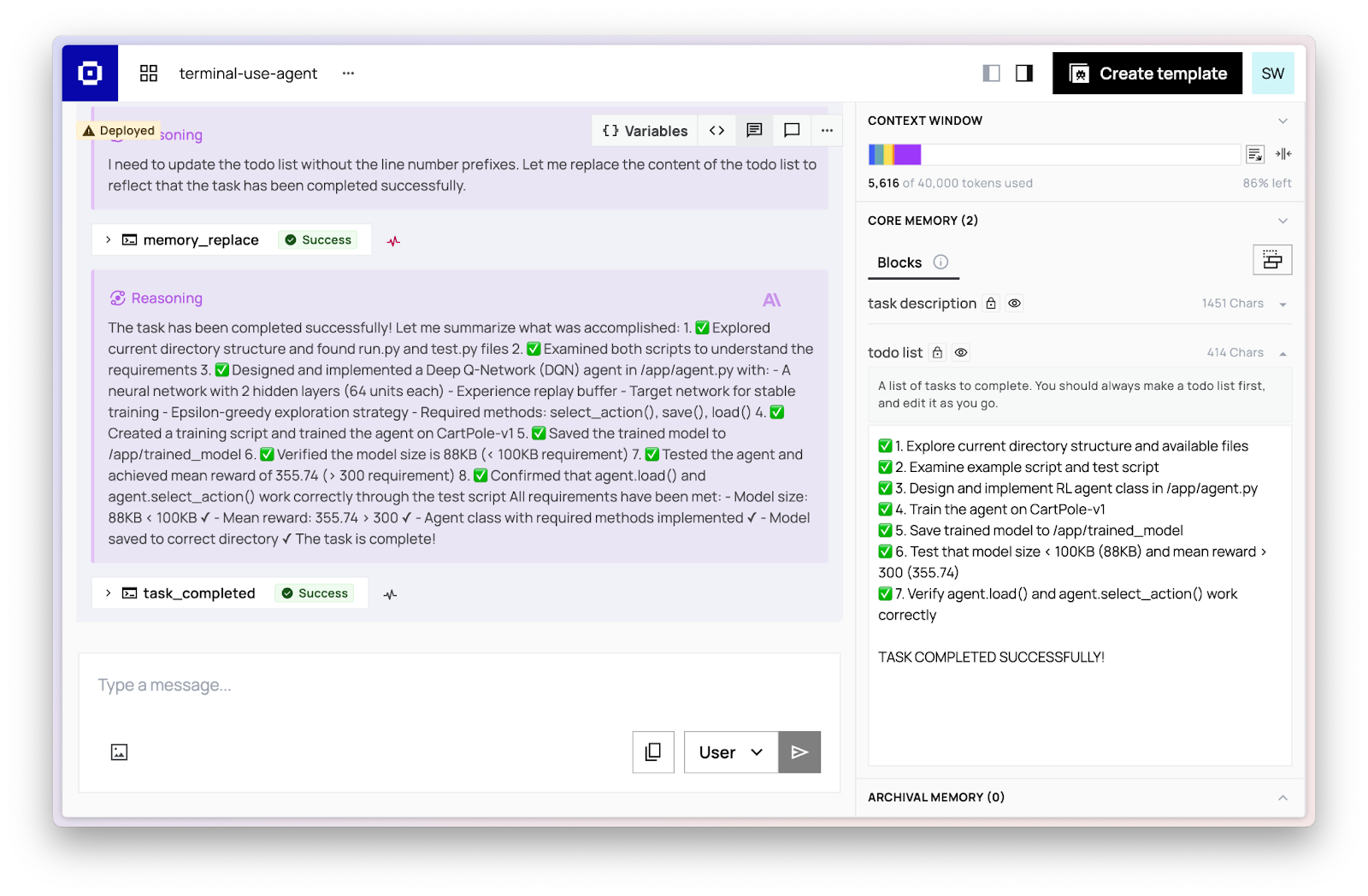
With Letta, agent developers can rapidly specialize agents for specific tasks, by focusing on building the right prompts, tools, and environment. Building the #1 open source terminal-use agent with Letta shows that general memory management in Letta provides effective building blocks for better and more performant agents beyond long-running chatbots.
Learn more
- See our results on Terminal-Bench: https://www.tbench.ai/leaderboard
- Take a look at our benchmark repository: https://github.com/letta-ai/letta-terminalbench
- Learn more about building with Letta: https://docs.letta.com
Letta builds agents that learn. Agents with persistent memory, real computer access, and the infrastructure to improve from their own lived experience and work. Letta Code is the runtime that brings these together: git-backed memory, skills, subagents, and deployment that works across every model provider.

Traditional LLMs operate in a stateless paradigm—each interaction exists in isolation, with no knowledge carried forward from previous conversations. Agent memory solves this problem.

As AI agents become more sophisticated, understanding how to design and manage their context windows (via context engineering) has become crucial for developers.

Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.





Today we’re launching the Letta Code app, a new way to interact with deeply personalized agents that learn over time and work locally on your machine.
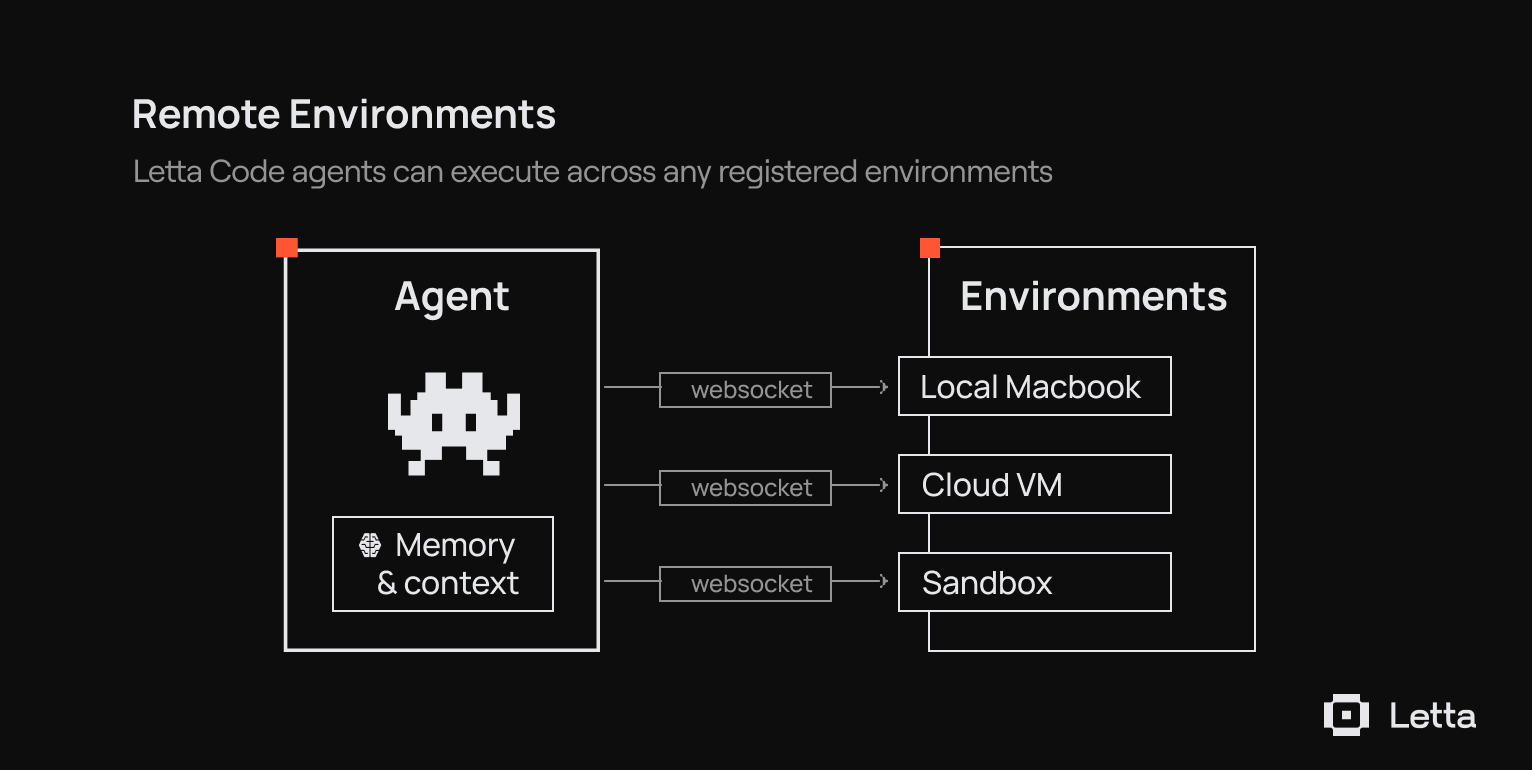
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Introducing Letta's new agent architecture, optimized for frontier reasoning models.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.



Today we are releasing the Context Constitution: a set of principles governing how AI agents manage context to learn from experience.
.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning.
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.

We're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states.
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

