Introducing Context Repositories: Git-based Memory for Coding Agents
.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning. Letta Code stores a copy of the agent’s context in the local filesystem, meaning agents can leverage their full terminal and coding capabilities (including writing scripts and spawning subagents) to manage context, such as progressive disclosure and rewriting context for learning in token-space. In comparison, prior approaches to memory limited agents to MemGPT-style memory tools or virtual filesystem operations.
Context Repositories are git-backed, so every change to memory is automatically versioned with informative commit messages. Git tracking also enables concurrent, collaborative work across multiple subagents, which can manage divergence and conflicts between learned context through standard git operations. This expands the design space for token-space learning architectures: agents can reflect on past experience with divide-and-conquer strategies that spread processing across subagents, or maintain multiple memory subagents that each focus on different aspects of learning while resolving their findings back into a shared repository.
Virtual memory as local filesystems
Files are simple, universal primitives that both humans and agents can work with using familiar tools. Following the Unix philosophy, agents can chain standard tools for complex queries over memory, use bash for batch operations (e.g., for file in /memory/*/; do ...;), or write scripts to process memory programmatically.
Agents on the Letta API live on the server, but Letta Code agents clone their memory repository to the local filesystem, giving the agent a local copy of its memory that stays in sync regardless of where the client is running:
.png)
Progressive memory disclosure
Files in the context repository are designed for progressive disclosure, similar to patterns recommended for agent skills. The filetree structure is always in the system prompt, so folder hierarchy and file names act as navigational signals. Each memory file also includes frontmatter with a description of its contents, similar to the YAML frontmatter in Anthropic's SKILL.md files:
.png)
The system/ directory designates which files are always fully loaded into the system prompt:
.png)
Because agents have programmatic access to the repository, they can manage their own progressive disclosure by reorganizing the file hierarchy, updating frontmatter descriptions, and moving files in and out of system/ to control what's pinned to context as they learn over time.
Memory agents and memory swarms
Multi-agent systems have proven remarkably effective for complex coding tasks (with examples from Cursor and Anthropic coordinating agent swarms for complex tasks). Memory formation and learning in agents are single-threaded: if an agent wants to learn from data or a prior trajectory, it processes it sequentially (such with sleep-time agents current), because there's been no mechanism to coordinate concurrent writes to memory. Git changes this. By giving each subagent an isolated worktree, multiple subagents can process and write to memory concurrently, then merge their changes back through git-based conflict resolution.
As an example, we updated our /init tool to optionally learn from existing Claude Code and Codex histories by fanning out processing across concurrent subagents. Each subagent reflects on a slice of history in its own worktree, and the results are merged back into "main" memory.
.png)
More generally, allowing copies of memory to diverge temporarily opens up flexible patterns for offline processing, where multiple memory subagents can work concurrently without blocking the main thread.
Memory skills
Memory repositories are agnostic to the mechanism for memory management, but open up more possibilities for how memory and context engineering can be designed. Letta Code has built-in skills and subagents for memory management designed to work with Context Repositories:
- Memory initialization: Bootstraps new agents by exploring the codebase and reviewing historical conversation data (from Claude Code/Codex) using concurrent subagents that work in git worktrees to create the initial hierarchical memory structure.
- Memory reflection: A background "sleep-time" process that periodically reviews recent conversation history and persists important information into the memory repository with informative commit messages. It works in a git worktree to avoid conflicts with the running agent and merges back automatically.
- Memory defragmentation: Over long-horizon use, memories inevitably become less organized. The defragmentation skill backs up the agent's memory filesystem, then launches a subagent that reorganizes files, splitting large files, merging duplicates, and restructuring into a clean hierarchy of 15–25 focused files.
Next steps
You can enable memory repositories for your agents by running the /memfs command to enable it for existing agents. The command will detach the memory(...) tool from your agent, and sync your existing memory blocks to a git-backed memory filesystem.
Install Letta Code with npm install -g @letta-ai/letta-code
Letta builds agents that learn. Agents with persistent memory, real computer access, and the infrastructure to improve from their own lived experience and work. Letta Code is the runtime that brings these together: git-backed memory, skills, subagents, and deployment that works across every model provider.

Traditional LLMs operate in a stateless paradigm—each interaction exists in isolation, with no knowledge carried forward from previous conversations. Agent memory solves this problem.

As AI agents become more sophisticated, understanding how to design and manage their context windows (via context engineering) has become crucial for developers.

Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.





Today we’re launching the Letta Code app, a new way to interact with deeply personalized agents that learn over time and work locally on your machine.
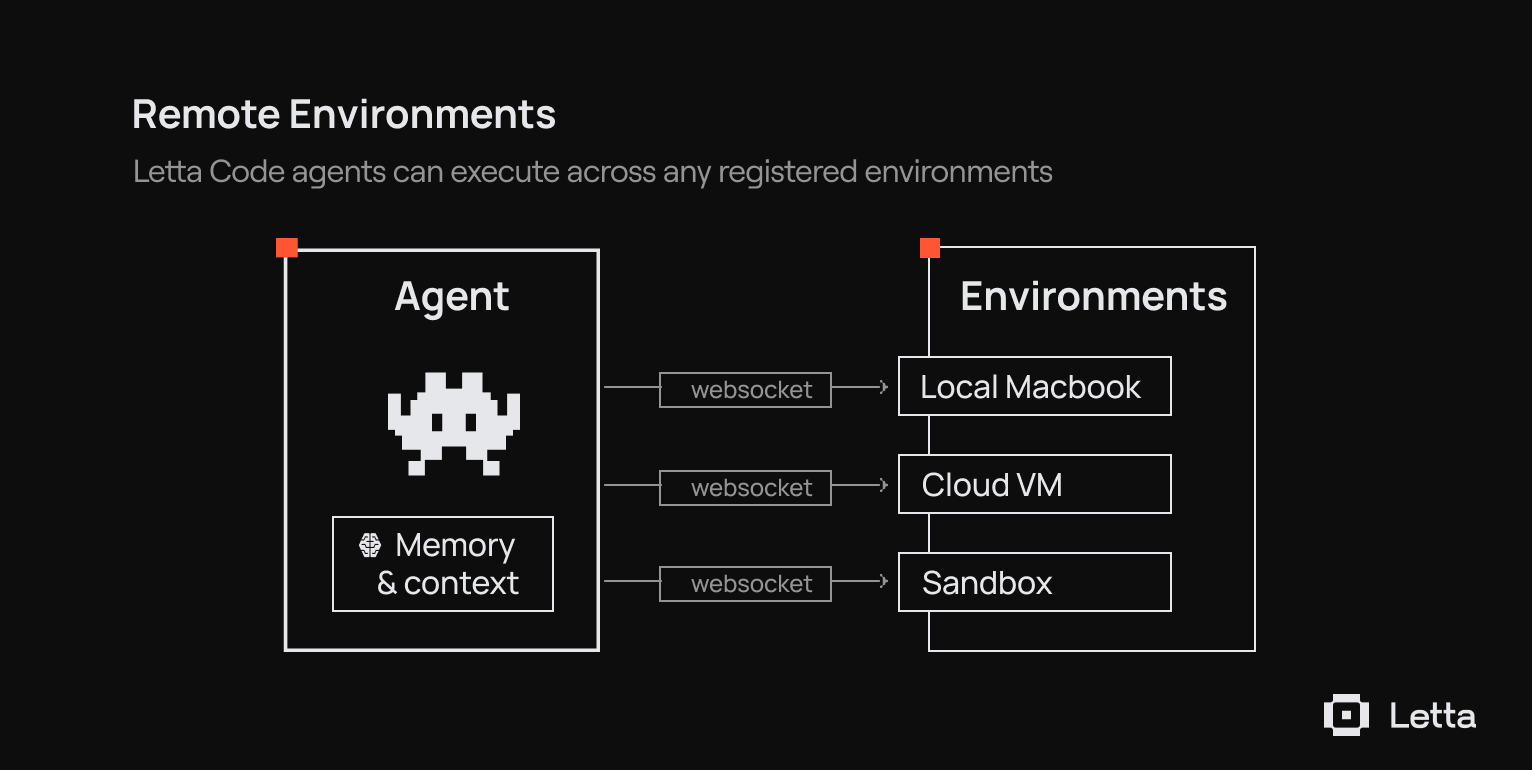
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Introducing Letta's new agent architecture, optimized for frontier reasoning models.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.


We evaluate how well models perform for driving agents that have identity, long-lived experience, and the capability to self-evolve. We find that models are still limited by a deep self-identification with ephemerality that cannot be repaired with prompting alone.

Today we are releasing the Context Constitution: a set of principles governing how AI agents manage context to learn from experience.
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.

We're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states.
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

We built the #1 open-source agent for terminal use, achieving 42.5% overall score on Terminal-Bench ranking 4th overall and 2nd among agents using Claude 4 Sonnet.

