Agent Memory: How to Build Agents that Learn and Remember

Traditional LLMs operate in a stateless paradigm — each interaction exists in isolation, with no knowledge carried forward from previous conversations. While this approach works basic tasks and short-lived agents, it fundamentally limits what AI systems can achieve. The shift from stateless LLMs to stateful agents represents an evolution towards systems that can actually learn and adapt over time.
What is Agent Memory?
Agent memory is what and how your agent remembers information over time. While basic memory might simply involve recalling previous interactions, advanced memory systems enable agents to learn and improve over time, adapting their behavior based on accumulated experience.
Agent Memory as Context Management
What your agent "remembers" is fundamentally determined by what exists in its context window at any given moment. Think of the context window as the agent's working memory — the information immediately available for answering questions, reasoning, and taking actions.
Therefore, designing an agent's memory is essentially context engineering: determining which tokens enter the context window and how they're organized. Memory systems compose multiple techniques (such as summarization, context rewriting, and retrieval) to manage various memory components (messages, memory blocks, and external databases).
Types of Agent Memory
Agent memory systems typically consist of several distinct components, each serving different purposes:
Message Buffer: Recent Messages
The message buffer stores the most recent messages in a conversation. In Letta, every agent maintains a single perpetual thread, which represents a continuous sequence of messages. This provides immediate conversational context and maintains dialogue flow.
Core Memory: In-Context Memory Blocks
Core memory consists of in-context memory blocks that can be managed by the agent itself or by other agents. These blocks focus on specific topics such as memories about the user, organization, or the current task. For example, one block might contain user preferences, while another maintains the agent's persona or current objectives. The key feature is that these blocks are editable via APIs and remain pinned to the agent's context window, providing an abstraction for managed context units.
Recall Memory: Conversational History
Recall memory preserves the complete history of interactions that can be searched and retrieved when needed, even when not in the active context window (i.e., in the message buffer). In Letta, recall memory saves to disk automatically, while other frameworks require developers to handle persistence manually.
Archival Memory: Explicitly Stored Knowledge
Archival memory represents explicitly formulated knowledge stored in external databases. Unlike recall memory, which stores raw conversation history, archival memory contains processed and indexed information. It can utilize different storage formats, such as vector databases or graph databases, with specialized tools that query and retrieve data back into the context window.
Techniques for Agent Memory
Message Eviction & Summarization
One fundamental challenge in agent memory is managing the limited context window. Summarization techniques help compress information while preserving essential details:
Eviction Methods: When the context window reaches capacity, intelligent eviction strategies determine what information to remove. This might involve summarizing and storing important details before removing them from active context. Generally, you should evict only a portion (e.g., 70%) of messages to ensure continuity.
Recursive Summarization: Evicted messages undergo recursive summarization—they're summarized along with existing summaries from previously summarized messages. As conversations grow longer, older messages have progressively less influence on the summary than recent messages.
Managing Memory Blocks
Memory blocks provide structured, editable storage within the agent's context window. Each block contains:
- A label
- A description (explaining what's stored in the block)
- A value (the actual tokens placed in context)
- A character limit (defining how much context window space is allocated)
Memory blocks abstract the context window for automated management. Agents can update their own memory blocks based on new information, using tools to rewrite specific blocks. Other agents specialized in memory management (such as sleep-time agents) can also modify these blocks. This creates a mechanism for context rewriting, allowing agents to improve their context window over time by consolidating important information.
External Storage & Retrieval
Memory can also be stored in external databases and retrieved via tool calling. Different storage and retrieval mechanisms suit different applications:
- Vector DBs: Memories are saved, embedded, and queried via vector search
- Graph DBs: Memories form graph structures where agents can traverse relationships between concepts, enabling sophisticated reasoning about connected information
While retrieval (or RAG) is a tool for agent memory, it is not “memory” in of itself.
Engineering Systems for Agent Memory
MemGPT: The Operating System Approach
MemGPT (MemoryGPT) is a system that intelligently manages different storage tiers to effectively provide extended context within the LLM's limited context window. MemGPT treats context windows as a constrained memory resource and implements a memory hierarchy similar to operating systems.

The system provides function calls that allow the LLM to manage its own memory autonomously. Agents can move data between in-context core memory (analogous to RAM) and externally stored archival and recall memory (analogous to disk storage), creating an illusion of unlimited memory while working within fixed context limits.
Sleep-Time Compute: Asynchronous & Specialized Memory Agents
Another approach to memory is using sleep-time agents to manage memory asynchronously. The sleep-time compute paradigm introduces several key improvements to the agent design from the original MemGPT paper:
- Non-Blocking Operations: Unlike MemGPT, where memory management, conversation, and other tasks are bundled into a single agent (potentially causing slower responses during memory operations), sleep-time agents handle memory management asynchronously, improving both response times and memory quality.
- Proactive Memory Refinement: Instead of lazy, incremental updates during conversations, memory can be reorganized and improved during idle periods.
This approach allows for higher quality memory blocks, enabling improved learning and memory formation over time – in addition to correlating the agent’s interaction latency.
Analogies Between Human and Agent Memory
While it's tempting to draw direct parallels between human and artificial memory, it's crucial to remember that LLMs are fundamentally text-in, text-out systems. Their "memory" consists solely of what exists in their context window.
Rather than hard-coding human-like memory structures, we should focus on context engineering — designing systems that effectively manage the information available to the model at inference time. This involves designing:
- How the context window is organized (determining message buffer size and memory block design)
- Tools for retrieving archival memory to pull externally stored context back into the window
- Prompts that help agents understand their memory limitations and leverage both in-context and external memory to overcome them
The goal isn't to replicate human memory mechanics but to create memory systems that enable agents to be genuinely helpful, consistent, and capable of learning within the token-based paradigm of LLMs.
Short-term vs. Long-term Agent Memory
An agent's “short-term” memory consists of whatever resides in the message buffer, as this content will eventually be evicted. All other memory types qualify as "long-term." However, it's more helpful to conceptualize agent memory as context engineering: understanding what is or isn't in the context window, and how tokens are pulled back into the context window. Ultimately, memory is about choosing which tokens to place in your context window at any given moment.
Conclusion
Agent memory represents one of the most critical frontiers in AI development. The future of agent memory lies not in any single technique but in the thoughtful combination of multiple approaches: careful eviction and summarization, intelligent management of memory blocks, and sophisticated systems for storing and retrieving external context.
If you’re looking to build agents that can form memories and learn over time to become more intelligent and personalized, check out the Letta API and Letta Code.
Letta builds agents that learn. Agents with persistent memory, real computer access, and the infrastructure to improve from their own lived experience and work. Letta Code is the runtime that brings these together: git-backed memory, skills, subagents, and deployment that works across every model provider.

As AI agents become more sophisticated, understanding how to design and manage their context windows (via context engineering) has become crucial for developers.

Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.





Today we’re launching the Letta Code app, a new way to interact with deeply personalized agents that learn over time and work locally on your machine.
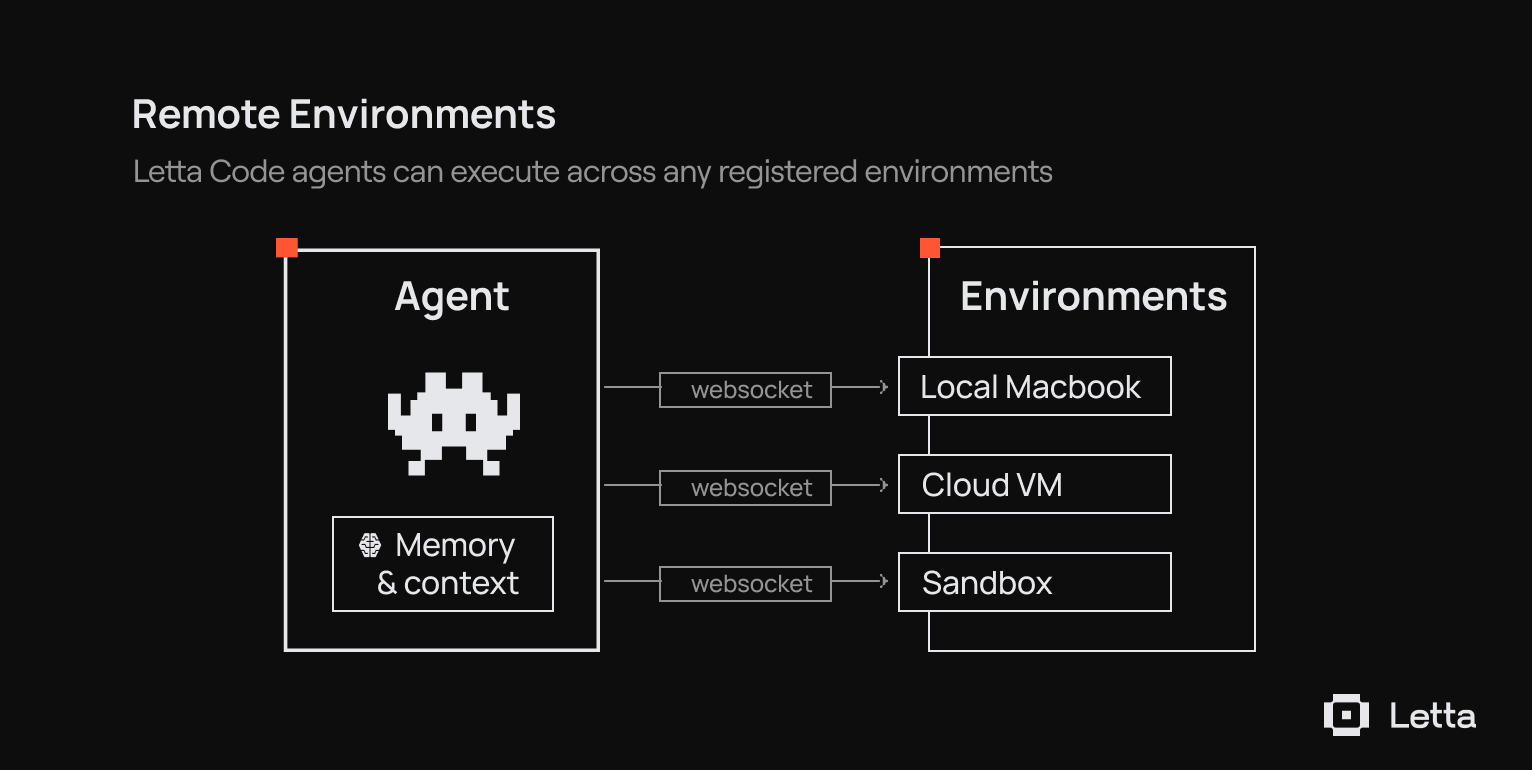
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Introducing Letta's new agent architecture, optimized for frontier reasoning models.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.


We evaluate how well models perform for driving agents that have identity, long-lived experience, and the capability to self-evolve. We find that models are still limited by a deep self-identification with ephemerality that cannot be repaired with prompting alone.

Today we are releasing the Context Constitution: a set of principles governing how AI agents manage context to learn from experience.
.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning.
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.

We're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states.
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

We built the #1 open-source agent for terminal use, achieving 42.5% overall score on Terminal-Bench ranking 4th overall and 2nd among agents using Claude 4 Sonnet.

