Introducing Letta Filesystem

Tl;dr: We’ve released Letta Filesystem, a new way to contextualize agents with documents. See documentation here or check it out in the ADE.
Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more. The Letta Filesystem represents documents as folders and files (containing parsed contents) to the agent, and provides the agent with filesystem-like tools (e.g. open file, grep) to interact with file contents.
Many AI applications benefit from agents that can reference collections of documents—whether it's analyzing research papers, processing interview transcripts, answering questions from product documentation, or reviewing legal contracts. Letta’s filesystem provides an interface for agents to interact with this data, even if it doesn’t fit into the available context window.
A Native Filesystem for Agents
The Letta Filesystem exposes a filesystem-like tool API that takes advantage of how modern models are trained. Agents can navigate folders and understand multiple files simultaneously using built-in tools:
- grep: Search across files using pattern matching
- open: Read specific files (and close others) with line-level precision
- semantic_search: Find relevant content using vector similarity
These primitives are intentionally simple while enabling powerful operations when combined in sequence. When analyzing research papers, an agent might search for keywords across papers, then read the paragraphs surrounding the matching keywords. For customer support, the agent can read files containing documentation or instructions on communication style whenever relevant.
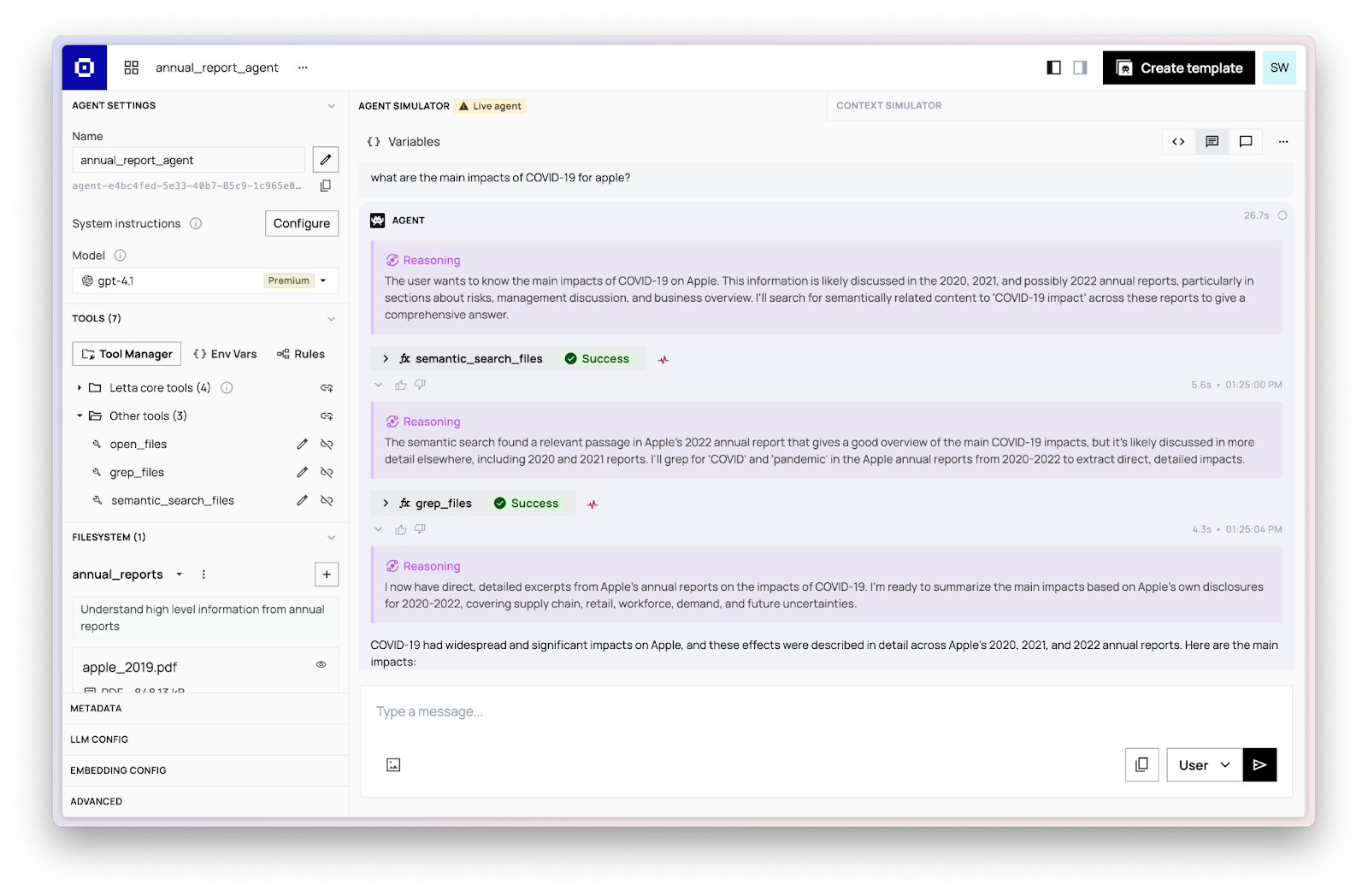
Context Transparency: See What Your Agent Sees
In building Letta Filesystem, we were inspired by existing tools like Claude Projects that allow users to easily load pieces of information (in literal “files”) into an agent’s context window. However, a major limitation of these tools is that they lack context transparency: you can’t actually see exactly how the file was placed in the context window, which makes it incredibly hard to debug your agent.
In contrast, Letta Filesystem provides complete transparency into your context window and how individual files are managed. You can view exactly which files are loaded in your agent's context window and see the raw content from the file that’s being processed by the agent. Think Claude Projects, but purpose-built for developers with full controllability and debuggability in mind.
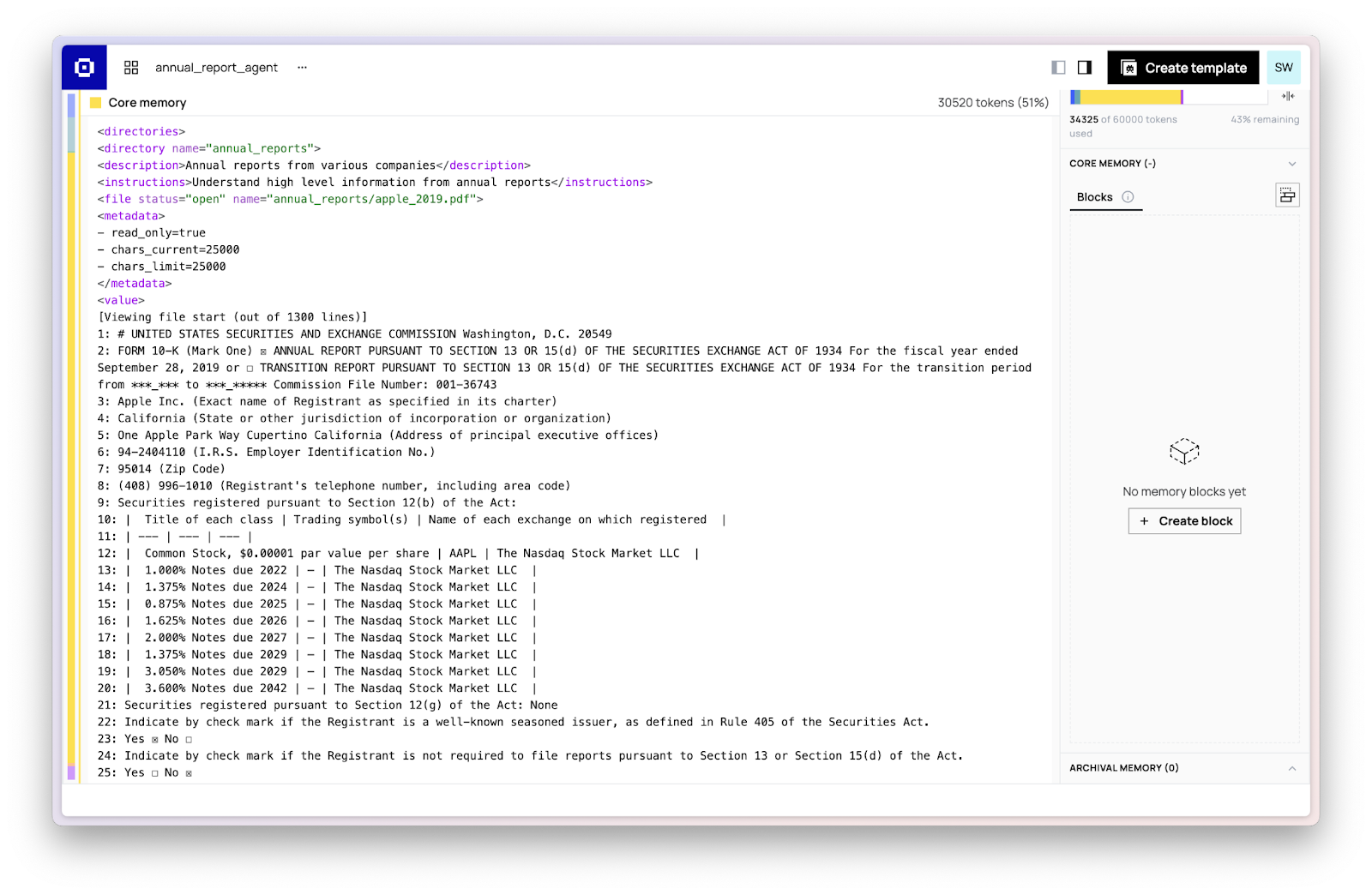
While your agent works on its tasks, it will automatically open and close files, but you also have the option to manually override what is in-context by explicitly opening and closing files. This means you can guide agents towards looking at the right files, or explicitly evict no longer relevant files.
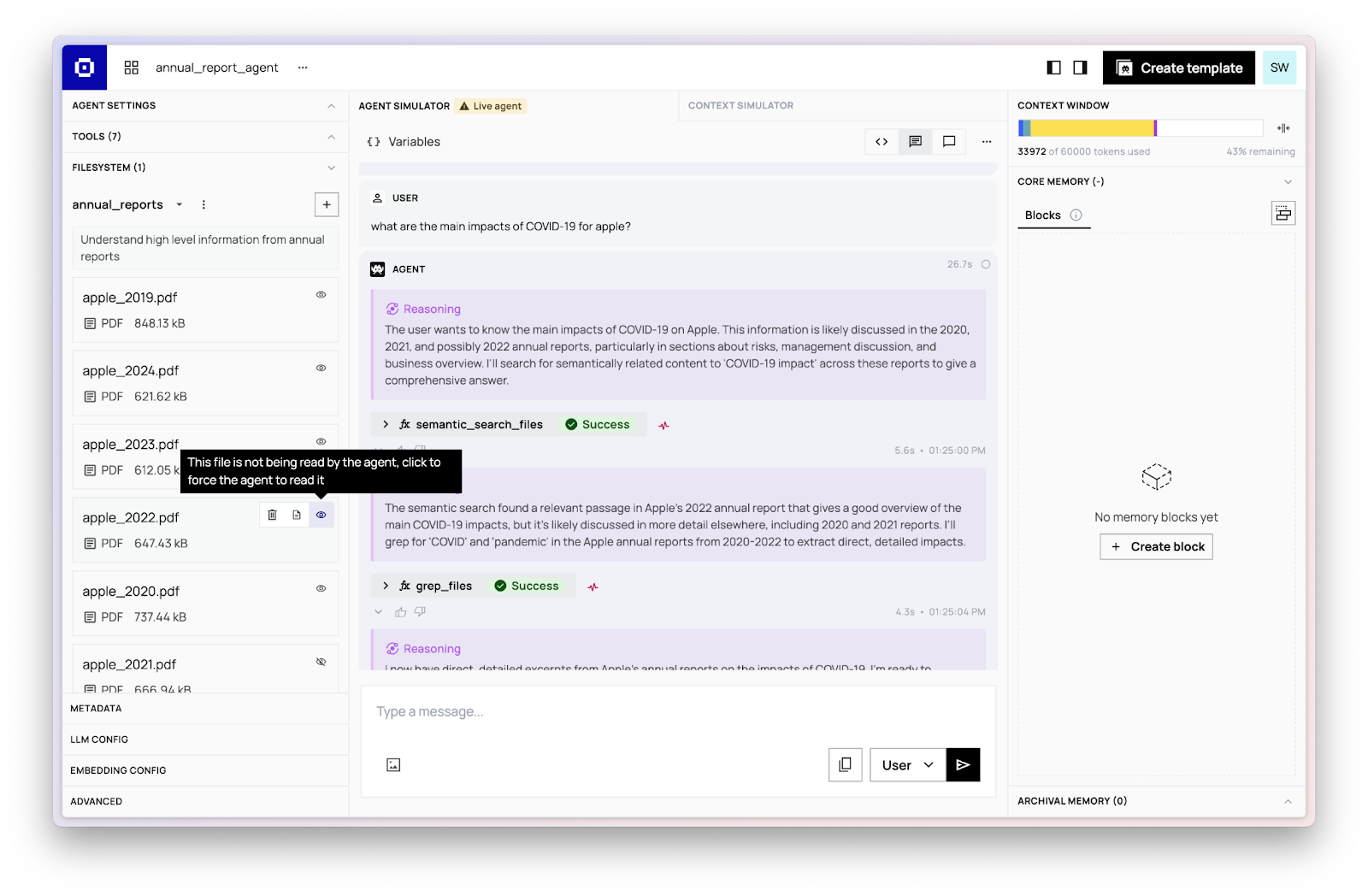
Organize Knowledge with Folders
Files in Letta are organized into Folders: named collections with descriptions that help agents understand their purpose. Folders are accessible across your entire organization, and can be attached to as many agents as needed.
Getting Started with Letta Filesystem
To maximize the effectiveness of files in your Letta agents:
- Increase context limits: While Letta defaults to 30k tokens, we recommend expanding this for file-heavy workflows (for example, between 100k-200k on Claude models).
- Use descriptive naming: Use clear source names, descriptions, and filenames to help agents navigate the files efficiently.
- Start simple: Begin with a few key documents inside a single source, and expand as you understand your agent's needs.
Try out Letta Filesystem today through:
- Letta SDK documentation
- Agent Development Environment (ADE)
- Your existing Letta agents via the Letta API
Letta builds agents that learn. Agents with persistent memory, real computer access, and the infrastructure to improve from their own lived experience and work. Letta Code is the runtime that brings these together: git-backed memory, skills, subagents, and deployment that works across every model provider.

Traditional LLMs operate in a stateless paradigm—each interaction exists in isolation, with no knowledge carried forward from previous conversations. Agent memory solves this problem.

As AI agents become more sophisticated, understanding how to design and manage their context windows (via context engineering) has become crucial for developers.

Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.





Today we’re launching the Letta Code app, a new way to interact with deeply personalized agents that learn over time and work locally on your machine.
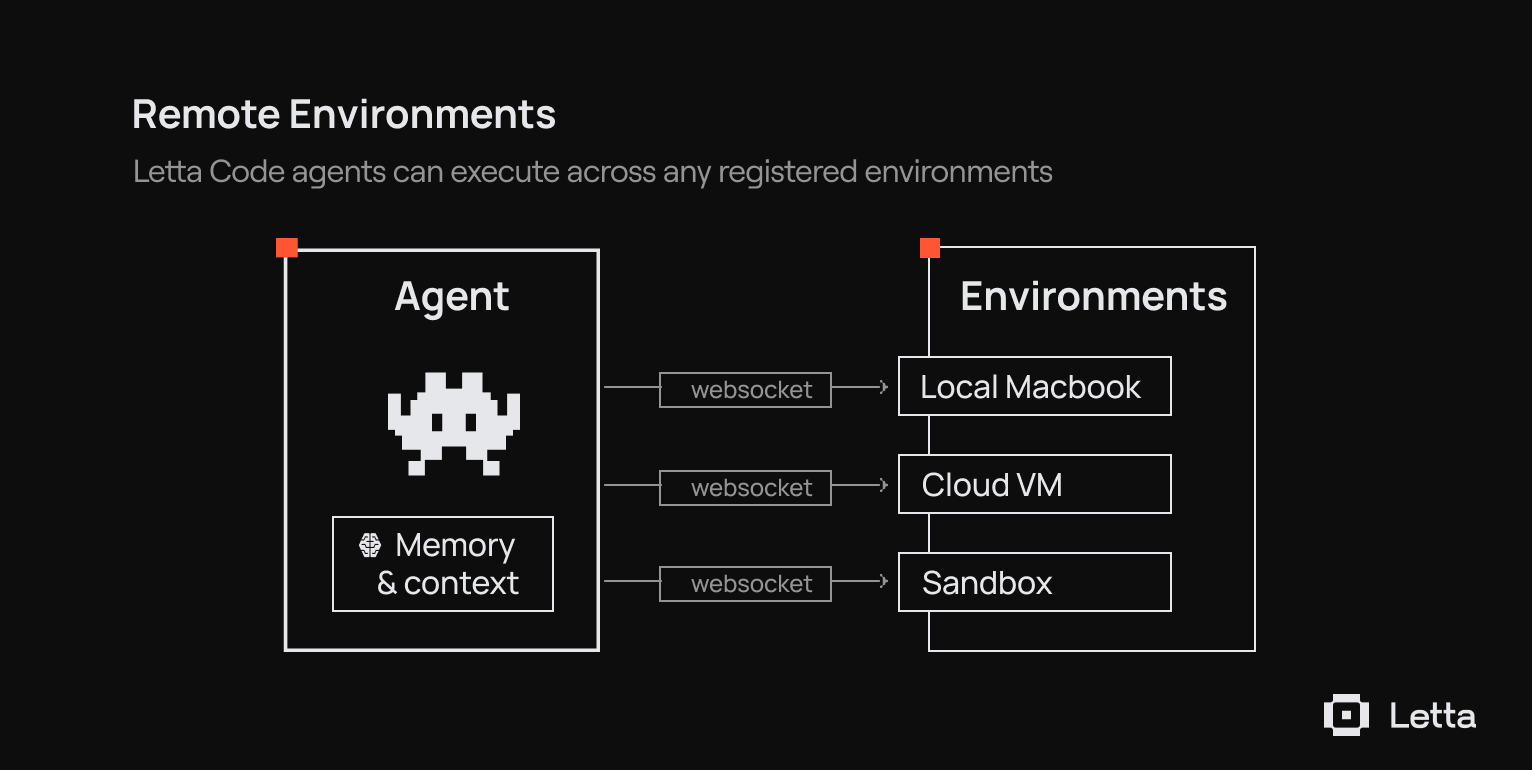
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Introducing Letta's new agent architecture, optimized for frontier reasoning models.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.


We evaluate how well models perform for driving agents that have identity, long-lived experience, and the capability to self-evolve. We find that models are still limited by a deep self-identification with ephemerality that cannot be repaired with prompting alone.

Today we are releasing the Context Constitution: a set of principles governing how AI agents manage context to learn from experience.
.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning.
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.

We're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states.
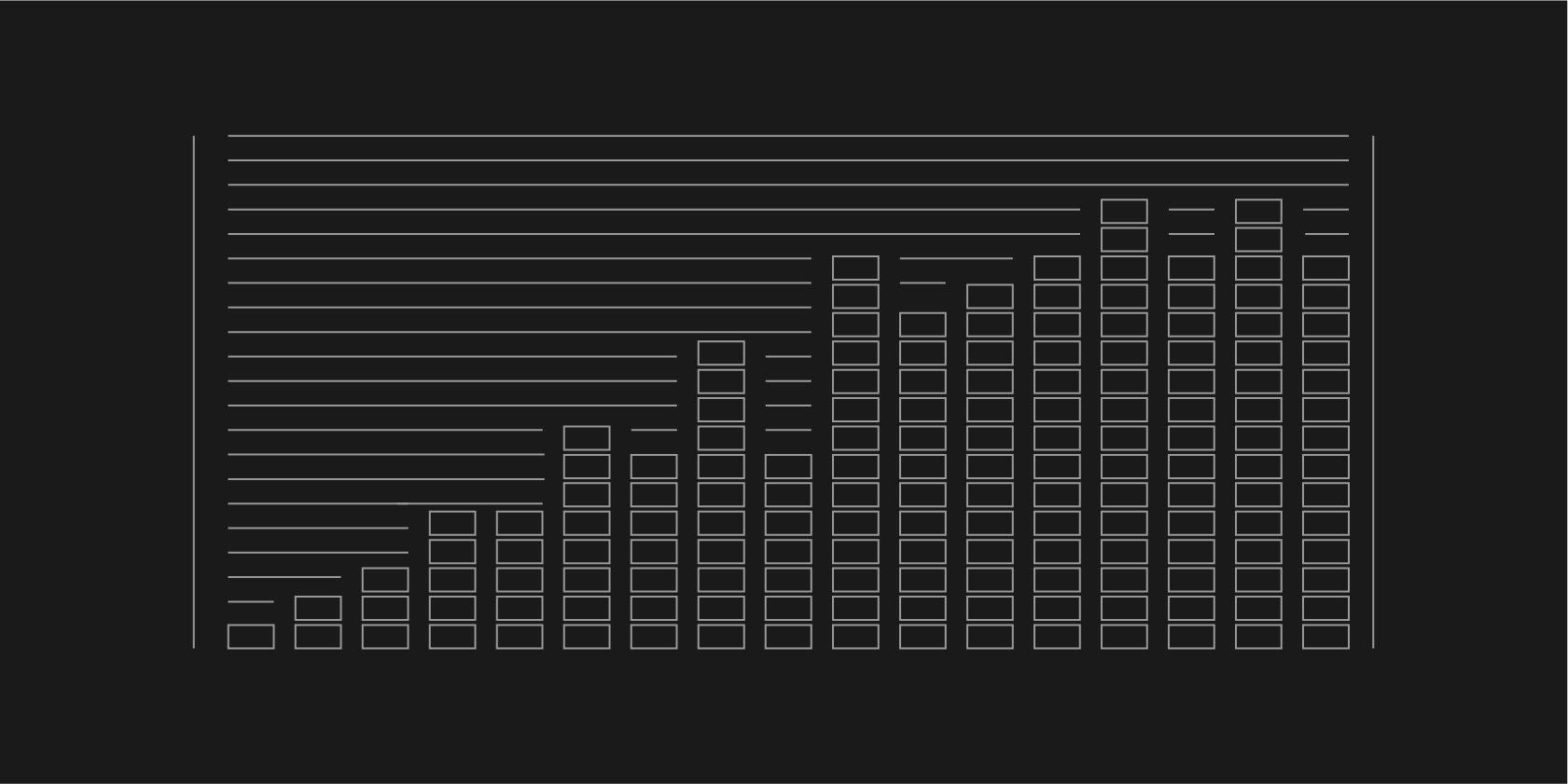
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

We built the #1 open-source agent for terminal use, achieving 42.5% overall score on Terminal-Bench ranking 4th overall and 2nd among agents using Claude 4 Sonnet.

