Introducing Recovery-Bench: Evaluating LLMs' Ability to Recover from Mistakes

"The only real mistake is the one from which we learn nothing." - Henry Ford
Long-lived agents will eventually make mistakes and need to recover. For example, a coding agent might implement the wrong solution, or a personal assistant may misunderstand instructions and execute an incorrect sequence of actions. In these cases, it's crucial that agents can recover (or ideally learn) from their mistakes, rather than suffer permanent performance degradation due to context pollution.
Today we're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states. We find that the best-performing models for long-term performance differ from the top performers in fresh states, with GPT-5 showing an especially significant improvement in ranking.

Background
Current agents excel at short-horizon tasks like small bug fixes, but their ability to independently execute complex long-horizon tasks remains limited. With long-horizon tasks, even the most capable frontier models will inevitably make errors at some point in their trajectory. Yet existing agent benchmarks evaluate agents starting from fresh environments. For example, coding agents are usually evaluated starting from a clean repository and GitHub issue. But in reality, coding agents work in messy environments containing files and edits from previous attempts to solve the task, erroneous reasoning traces from debugging sessions, and other artifacts.
Recovery-Bench is a new benchmark that bridges this gap by evaluating agents in more realistic environments that include existing trajectories from previous attempts. Failed trajectories represent opportunities for agents to learn from their mistakes, but our research reveals a counterintuitive finding: the best AI models today are often distracted or misled by failed trajectories in their context, suffering from context pollution.
Context pollution refers to the leftover artifacts of an agent’s failure. It can include erroneous actions, misleading reasoning traces, or corrupted environment states that persist into an agent’s working context. For instance, a coding agent might inherit a broken function or misapplied patch from an earlier attempt, leading it to compound errors rather than correct them.
Our results highlight that recovery represents a distinct capability from performance in fresh states. Claude 4 Sonnet, which tops standard evaluations, drops in rank under recovery conditions, while GPT-5 moves ahead—showing that resilience to context pollution is not correlated with raw problem-solving strength.
Building Recovery-Bench
Recovery-Bench provides a general and simple methodology for measuring agent recovery: how well an agent can successfully complete a task by recovering from previous failures.
We select a long-horizon task and ask a weaker agent to solve it in the standard setting with a clean environment. We then filter the resulting trajectories (the full sequences of actions an agent takes and the environment states those actions produce), keeping only those where the agent failed to complete the task. Finally, we evaluate how well other agents can recover by initializing them with the actions and environment left behind by these failed trajectories.
Recovery-Bench-v0 uses tasks from Terminal-Bench, a challenging benchmark for measuring agents' capabilities at using the terminal. We first collect trajectories from gpt-4o-mini, then evaluate a variety of models (GPT-5, Gemini 2.5 Pro, Claude 4 Sonnet, o4-mini, GPT-4.1) on agent recovery tasks.
How Challenging Is Recovery?
Agent recovery tasks are challenging even for the strongest models. In the original Terminal-Bench setting, models scored an average of 26.3%, with the best model, Claude 4 Sonnet, reaching 34.8%. On Recovery-Bench, models score an average of only 11.2%. Compared to their performance on the original Terminal-Bench, they show a 57% relative decrease in accuracy.
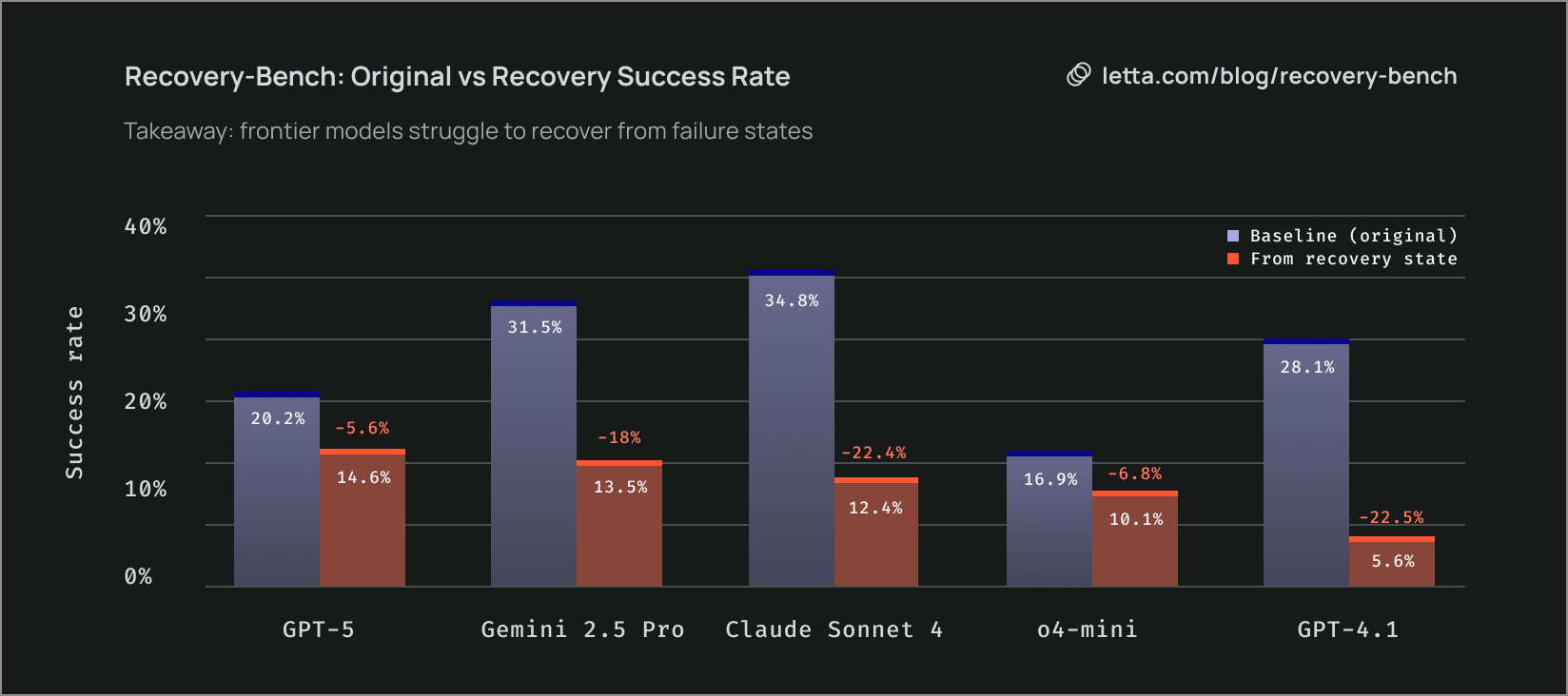
Is Agent Recovery a Standard Capability?
We show that the rankings on Recovery-Bench differ from standard Terminal-Bench settings, indicating that recovery represents an orthogonal capability. For example, Claude 4 Sonnet achieves the highest Terminal-Bench score at 34.8% but ranks third on Recovery-Bench, while GPT-5 achieves only 20.2% on the original Terminal-Bench but ranks first on Recovery-Bench. Interestingly, o4-mini has the lowest Terminal-Bench score but performs significantly better than GPT-4.1 on agent recovery.
What's in a Recovery State?
Recovery states contain two distinct components: environments and action histories. In Terminal-Bench, actions correspond to commands sent to the terminal (e.g., ls) and the resulting terminal states. In realistic settings, agents need to recover from both the modified environment and erroneous actions present in their context.
To better understand what makes Recovery-Bench challenging, we study three different settings that initialize the recovery agent with different components:
- Environment: The environment is set to the state after a failed agent trajectory, but the new agent receives no additional context about the initial trajectory
- Environment + Action Summary: In addition to the environment, the agent receives a summary of the previous actions
- Environment + Action History: In addition to the environment, the agent receives the full actions from the initial failed trajectory
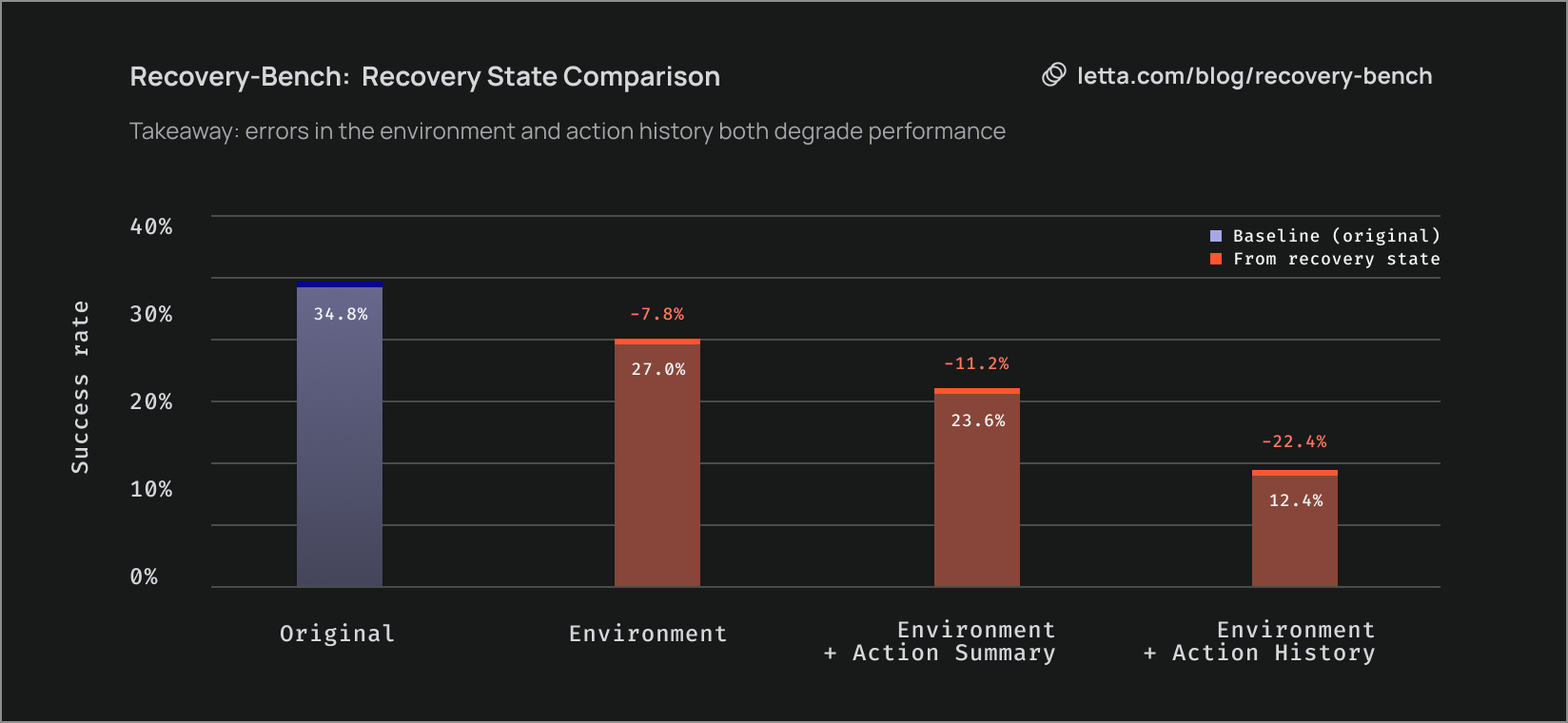
In our benchmark results, we observe that providing just the environment already significantly degrades agent performance compared to the original setting. Giving the agent both the environment and action summary further degrades performance. Interestingly, providing the full action history yields the worst performance, showing that displaying the actions directly doesn't immediately help resolve errors in the environment. Taken together, our results show that Recovery-Bench's challenge stems from both recovering from erroneous actions affecting the environment and managing context pollution from errors in the action history.
Future Work
Our initial results make it clear that today’s frontier models lack the ability to naturally recover from failed states, a key ingredient for continual learning. Our research also suggests that agents may benefit from using different models at different points within a single trajectory, as well as robust context management systems (like those in Letta) that enable the agent to learn from failed trajectories rather than be distracted by them.
We also plan to expand the current methodology for building Recovery-Bench to include tasks beyond Terminal-Bench, including SWE-Bench and other agent benchmarks, to more broadly understand how agents recover. We expect to observe different phenomena in domains beyond terminal use.
At Letta, we are building self-improving, perpetual agents that can learn from experience and adapt over time. If you’re excited by our mission and want to contribute towards work like Recovery-Bench, apply to join our team.
Learn More
- GitHub repository: https://github.com/letta-ai/recovery-bench
- Building stateful agents with Letta: https://docs.letta.com
- Letta Platform: https://app.letta.com
Letta builds agents that learn. Agents with persistent memory, real computer access, and the infrastructure to improve from their own lived experience and work. Letta Code is the runtime that brings these together: git-backed memory, skills, subagents, and deployment that works across every model provider.

Traditional LLMs operate in a stateless paradigm—each interaction exists in isolation, with no knowledge carried forward from previous conversations. Agent memory solves this problem.

As AI agents become more sophisticated, understanding how to design and manage their context windows (via context engineering) has become crucial for developers.

Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.





Today we’re launching the Letta Code app, a new way to interact with deeply personalized agents that learn over time and work locally on your machine.
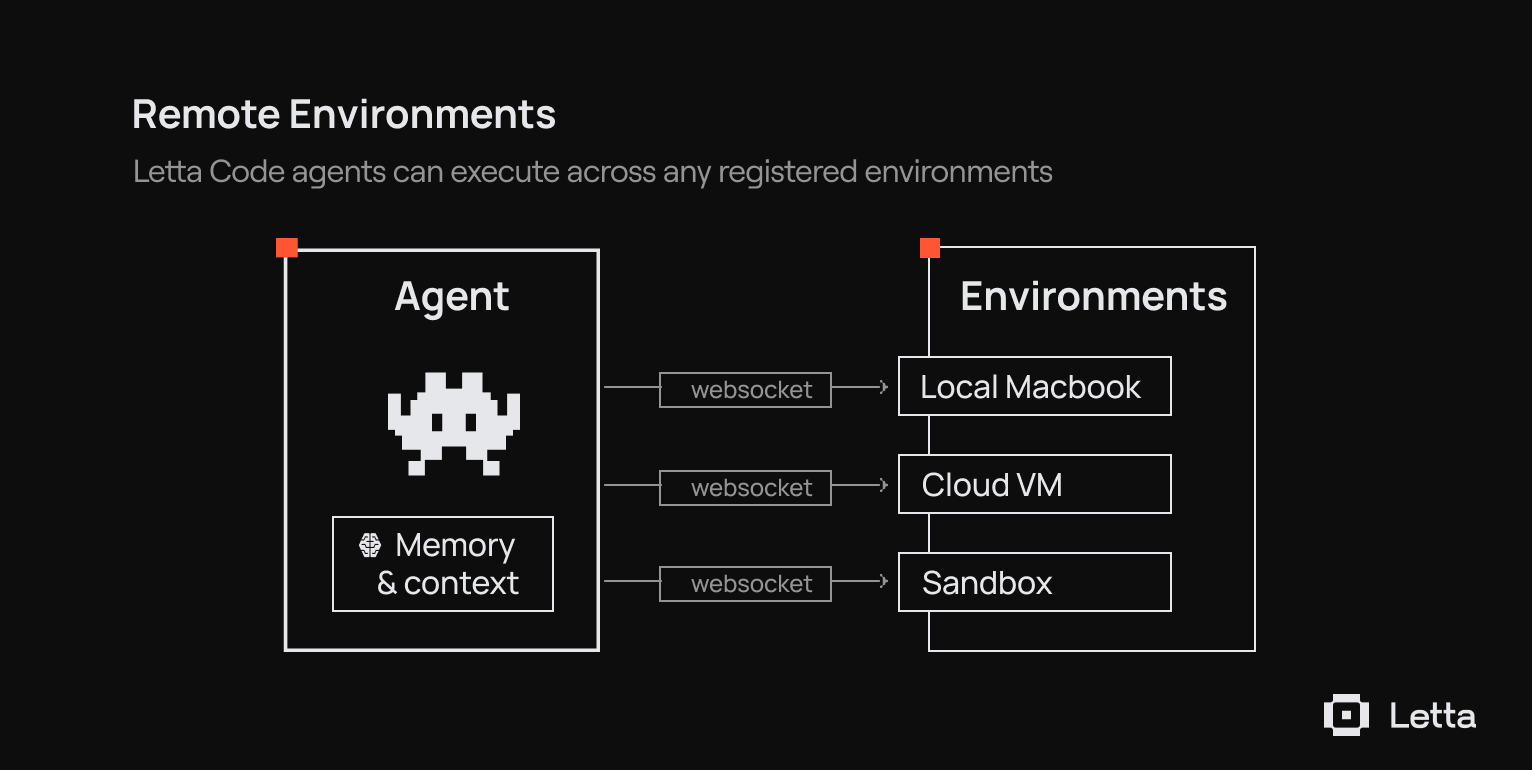
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Introducing Letta's new agent architecture, optimized for frontier reasoning models.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.


We evaluate how well models perform for driving agents that have identity, long-lived experience, and the capability to self-evolve. We find that models are still limited by a deep self-identification with ephemerality that cannot be repaired with prompting alone.

Today we are releasing the Context Constitution: a set of principles governing how AI agents manage context to learn from experience.
.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning.
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

We built the #1 open-source agent for terminal use, achieving 42.5% overall score on Terminal-Bench ranking 4th overall and 2nd among agents using Claude 4 Sonnet.

