Memory Blocks: The Key to Agentic Context Management

Large language models (LLMs) face a fundamental constraint: they can only "see" what's in their immediate context window. This limitation creates a critical challenge when building applications that require long-term memory and coherence across interactions. The effectiveness of an LLM agent largely depends on how well its context window is managed - what information is kept, what is discarded, and how it's organized.
Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory. This concept, which originated in the MemGPT research paper and Letta agents framework, provides a systematic approach to organizing what information an LLM has access to during inference.
Memory Blocks: A Powerful Abstraction for Agent Memory
The idea of an agent that could manage its own memory (including its own context window) originated in the MemGPT paper. MemGPT demonstrated the idea of self-editing memory in a simple chat use-case with two in-context memory blocks:
- “Human” memory block: Storing information about the user, their preferences, facts about them, and relevant context.
- “Persona” memory block: Containing the agent's own self-concept, personality traits, and behavioral guidelines.
These blocks were editable by the agent, and also restricted to a certain character limit (to limit context window allocation to those memories). These blocks provided a way to allocate certain parts of the context window to store important information about specific topics.
For example, the agent can edit the “human” block as it learns more about them. And by editing the “persona” block, the agent could make sure to persist certain personality traits or “identity” features. If the agent stated a preference for vanilla ice cream, it could write it to the persona block to make sure it would be consistent in the future when asked about its favorite flavor.
Why Context Window Management Matters
Before diving deeper into memory blocks, it's important to understand why effective context window management is crucial for LLM applications:
- Better performance: LLMs are sensitive to what's in their context window. They can't reason about information they don't "see" at inference time. By carefully managing which information is present in the context (e.g. by having it curated by another agent), we can dramatically improve the performance of agents.
- Personalization & adaptability: For agents that serve specific users or functions, maintaining the right information in context is essential for providing tailored experiences. Without proper context management, agents either forget critical user information or must redundantly ask for it in each step of the interaction.
- Controllability: By structuring the context window into distinct blocks with specific purposes, developers gain greater control over agent behavior. This structured approach allows for more predictable and consistent agent responses, and defining mechanisms for long-term context management in agents.
Memory Blocks are Units of Agent Memory
Rather than treating the context window as a monolithic entity, memory blocks break the context window down into manageable, purposeful units that are also persisted. A memory block consists of:
- A label that identifies its purpose (e.g., "human", "persona", "knowledge")
- A value that is the string representation of the block data
- A size limit (e.g. in characters or tokens) that dictates how much of the context window it can occupy
- Optional descriptions that guide how the block should be used
The block value can be edited by the agent via memory tools (or custom tools), unless they are read-only: in which case, only the developer can modify them.
Editing Memory Blocks via the Letta API
Unlike ephemeral memory in many LLM frameworks, Letta's memory blocks are individually persisted in the DB, with a unique `block_id` to access them via the API and Agent Development Environment (ADE). This provides a way for developers to directly modify parts of their agent’s context window.
When Letta makes a request to the LLM, the context window is “compiled” from existing DB state, including current block values. The prompt template (i.e. formatting in the context window) can be customized with Jinja templating.
Multi-Agent Shared Memory
One of Letta's most powerful features is the ability for multiple agents to share memory blocks:
.png)
This enables sophisticated patterns like:
- Shared knowledge bases: Multiple agents accessing the same reference information
- Sleep-time compute: Background agents updating the memory of primary agents
- Collaborative memory: Teams of agents maintaining a shared understanding
Tool-Based Memory Editing
Memory blocks can be modified through a variety of tools to customize memory management. Below is an example of a custom tool to “rethink” (replace) an entire memory block’s value by specifying the new block value and the target block label:
.png)
Because memory block values are just strings, you can store more complex data structures like lists or dictionaries in blocks, as long as they can be represented into a string format.
Practical Applications
The flexibility of Letta's memory block system enables a wide range of powerful applications:
Personalized Assistants
By maintaining detailed user information in a human memory block, assistants can remember preferences, past interactions, and important details about each user:
.png)
Sleep-Time Agents
As we demonstrated in our Sleep-time Compute research, agents can process information during idle periods and update shared memory blocks. For example, a sleep-time agent might reflect on an existing codebase (similar to Cursor’s background agents) or previous conversation history to form new memories (referred to as “learned context”) in the paper. Learned context is written to a memory block in Letta, and can be shared across multiple agents.
Long-running Agents (e.g. Deep Research)
For complex, long-running agents like deep research agents, the context must maintain the state of the task across multiple LLM invocations without derailment. 11x’s deep research agent benefitted from writing the “research state” into a memory block to track research progress.
Conclusion
Building powerful, reliable agents that can learn and improve over time will require developing techniques for context management over time. Memory blocks provide a unit of abstraction for storing and managing sections of the context window. By breaking the context window into purposeful, manageable units, we enable agents that are more capable, personalized, and controllable.
Ready to experience the power of memory blocks for yourself? Get started today with the Letta API and Letta Code.
Letta builds agents that learn. Agents with persistent memory, real computer access, and the infrastructure to improve from their own lived experience and work. Letta Code is the runtime that brings these together: git-backed memory, skills, subagents, and deployment that works across every model provider.

Traditional LLMs operate in a stateless paradigm—each interaction exists in isolation, with no knowledge carried forward from previous conversations. Agent memory solves this problem.

As AI agents become more sophisticated, understanding how to design and manage their context windows (via context engineering) has become crucial for developers.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.





Today we’re launching the Letta Code app, a new way to interact with deeply personalized agents that learn over time and work locally on your machine.
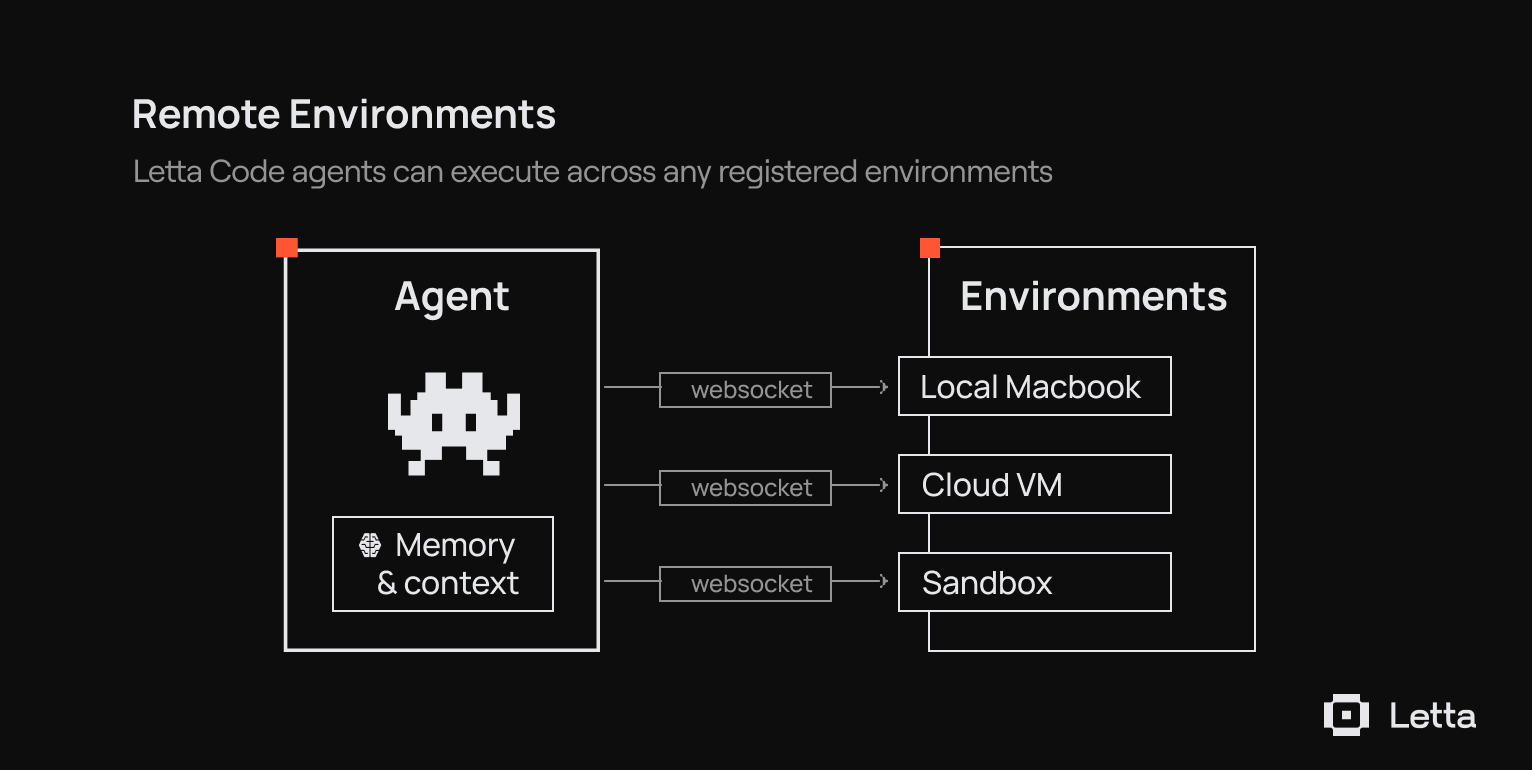
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Introducing Letta's new agent architecture, optimized for frontier reasoning models.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.


We evaluate how well models perform for driving agents that have identity, long-lived experience, and the capability to self-evolve. We find that models are still limited by a deep self-identification with ephemerality that cannot be repaired with prompting alone.

Today we are releasing the Context Constitution: a set of principles governing how AI agents manage context to learn from experience.
.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning.
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.

We're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states.
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

We built the #1 open-source agent for terminal use, achieving 42.5% overall score on Terminal-Bench ranking 4th overall and 2nd among agents using Claude 4 Sonnet.

