Anatomy of a Context Window: A Guide to Context Engineering

Context engineering – the practice of designing how an agent's context window is structured and dynamically modified – is becoming increasingly important as agents become long-running and stateful, rather than just simple workflows.
Context is a valuable resource, and requires careful context engineering to design how the context window is managed over time. But to engineer context, we first need to break down the actual components (or “anatomy”) of a context window, and how these components are managed over time.
Breaking down an agent’s context window
An agent’s context window consists of the following components:
- System prompt: Defines the agent's architecture and control flow, providing high-level behavioral instructions and explaining core concepts like memory, blocks, and files.
- Tool schemas: Specifications that define available tools and their interfaces, enabling the agent to understand what actions it can perform.
- System metadata: Stores statistics and metadata about the agent’s state (e.g. the size of the full message history) .
- Memory blocks: Persistent units of context (e.g. for long term memory or working context), managed by the agent itself or other background agents.
- Files & Artifacts: Files (PDFs, source code, etc.) that the agent can access and manipulate.
- Message buffer: The message stream containing messages (user, assistant, and system, and tool calls and tool returns).
Context management refers to both how this context window is designed (through configuration of files, blocks, tools, and prompts), as well as how this context window evolves over time. The context window can be controlled directly by the underlying system (the “LLM OS” or “AI OS”) or with agentic tool calling (which is executed by the OS).
For example, external context can be pulled into the context window via tools, such as with MCP (Model Context Protocol) or built-in tools for conversational or file search:

Tool calls can also be used to modify specific parts of the context window, such as memory blocks or file blocks:

Designing these mechanisms for context arrangement and evolution over time is what we refer to as “context engineering”, and is what defines the long-term behavior of your agents.
The LLM Operating System: Automated Context Engineering
To understand context engineering, it's helpful to think of frameworks like Letta as an LLM OS — an operating system for language models. Just as traditional operating systems manage hardware resources (CPUs, GPUs, I/O devices) and provide abstractions for applications to use the underlying hardware, an LLM OS manages context windows and provides abstractions for context engineering the underlying LLM.
In a traditional operating system, resources are scoped into multiple layers:

Like resources in traditional operating systems, in an LLM OS, context is scoped to the application layer (i.e. user space) and the system layer (i.e. kernel space):
- Kernel Context - Managed context that can be modified through APIs and tool calling (like kernel memory). This represents the underlying agent configuration (the system prompt and tools), as well as managed context such as memory blocks and files.
- User Context - The message buffer containing conversations and external context (like user processes), as well as system calls (tools) to modify the kernel context.

Kernel Context: System-Managed Context
Kernel context represents the managed, mutable state of an agent—analogous to kernel memory in an operating system. This layer enables agents to maintain memory and work with persistent data structures that evolve over time. Crucially, the kernel context is rendered into the context window where the LLM can observe it, but modifications happen through controlled interfaces.
The System Call Interface
Just as operating systems provide system calls for user processes to interact with kernel space, the LLM OS provides built-in tools that act as the system call interface:
- Memory operations: Tools like memory_replace, memory_rethink, and memory_append allow controlled modification of memory blocks
- File operations: Tools like open, close, and grep manage file state in kernel space
- Custom operations: Custom tools can call APIs to modify underlying state
Combining these tools allows for management of agent context windows via the LLM. These tools can be used both by the agent itself to manage its own memory and context, or by other specialized agents (e.g. sleep-time agents which process information in the background).
Memory Blocks
Introduced by MemGPT, memory blocks are reserved portions of the context window designed for persistent memory. Each memory block has several key properties:
- Size limits: Hard constraints preventing overflow
- Labels and descriptions: Metadata that guides what information should be stored
- Access patterns: Including read-only flags for protected memory
Memory blocks enable agents to maintain state across conversations, learn from interactions, and build up knowledge over time, and can also be used as “working memory” to achieve complex tasks like deep research. Memory blocks can also be shared across multiple agents.
Files
Files provide a familiar abstraction for data management within the context window. The file metaphor is particularly powerful because many LLMs are post-trained on coding tasks, making them naturally adept at file operations. Files can be "open" (loaded into context) or "closed" (stored with metadata only), and also searched with common operations like vector search or grep, which translates well to agent capabilities
Artifacts represent a special category of editable files (often with extra dependencies or file groupings). These allow agents to iteratively modify content—whether code, documentation, or creative writing—through successive refinements.
User Context: The Message Buffer
The user context, or message buffer, represents the "user space" of our LLM OS. Like processes in a traditional OS, this is where the actual work happens—conversations unfold, tools are called, and the agent interacts with the outside world. Tools in the user-space can be used to pull in external context (e.g. via MCP) or modify context in the kernel space.
The buffer contains several message types:
- User messages: Direct input from users
- Assistant messages: The agent's responses
- System messages: Framework or system-generated notifications (like system logs)
- Tool calls and responses: The log of both system calls and other tools, as well as their results
Tool Categories: System Calls vs User Programs
In our OS analogy, tools fall into two distinct categories:
System Tools (Built-in system calls) are provided by the LLM OS itself and have privileged access to modify agent state internals reflected in the compiled kernel context (blocks & files).
Custom Tools (User programs) are defined by developers and run in user space with limited privileges. They serve as the primary mechanism for dynamically pulling in external context, such as through:
- Search tools for real-time information or accessible external data
- Model Context Protocol (MCP) for standardized context retrieval
These custom tools act as the agent's gateway to the outside world, pulling relevant external information into the context window while maintaining the integrity of the kernel state through proper system call interfaces.
Context Engineering & Agent Memory
Proper context management and engineering allows you to build agents that actually have long term memory and the ability to use their memory to solve more complex tasks and learn over time. Context and memory management make it possible to build agents that improve, rather than derailing and degrading.
Conclusion
You can get started with building agents with proper context engineering with Letta. The Agent Development Environment (ADE) makes it easy to visualize your context window so you can engineer your agent’s context to access long-term memory, large data sources and files, and external tools via MCP.
Get started today with the Letta API and Letta Code.
Letta builds agents that learn. Agents with persistent memory, real computer access, and the infrastructure to improve from their own lived experience and work. Letta Code is the runtime that brings these together: git-backed memory, skills, subagents, and deployment that works across every model provider.

Traditional LLMs operate in a stateless paradigm—each interaction exists in isolation, with no knowledge carried forward from previous conversations. Agent memory solves this problem.

Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.





Today we’re launching the Letta Code app, a new way to interact with deeply personalized agents that learn over time and work locally on your machine.
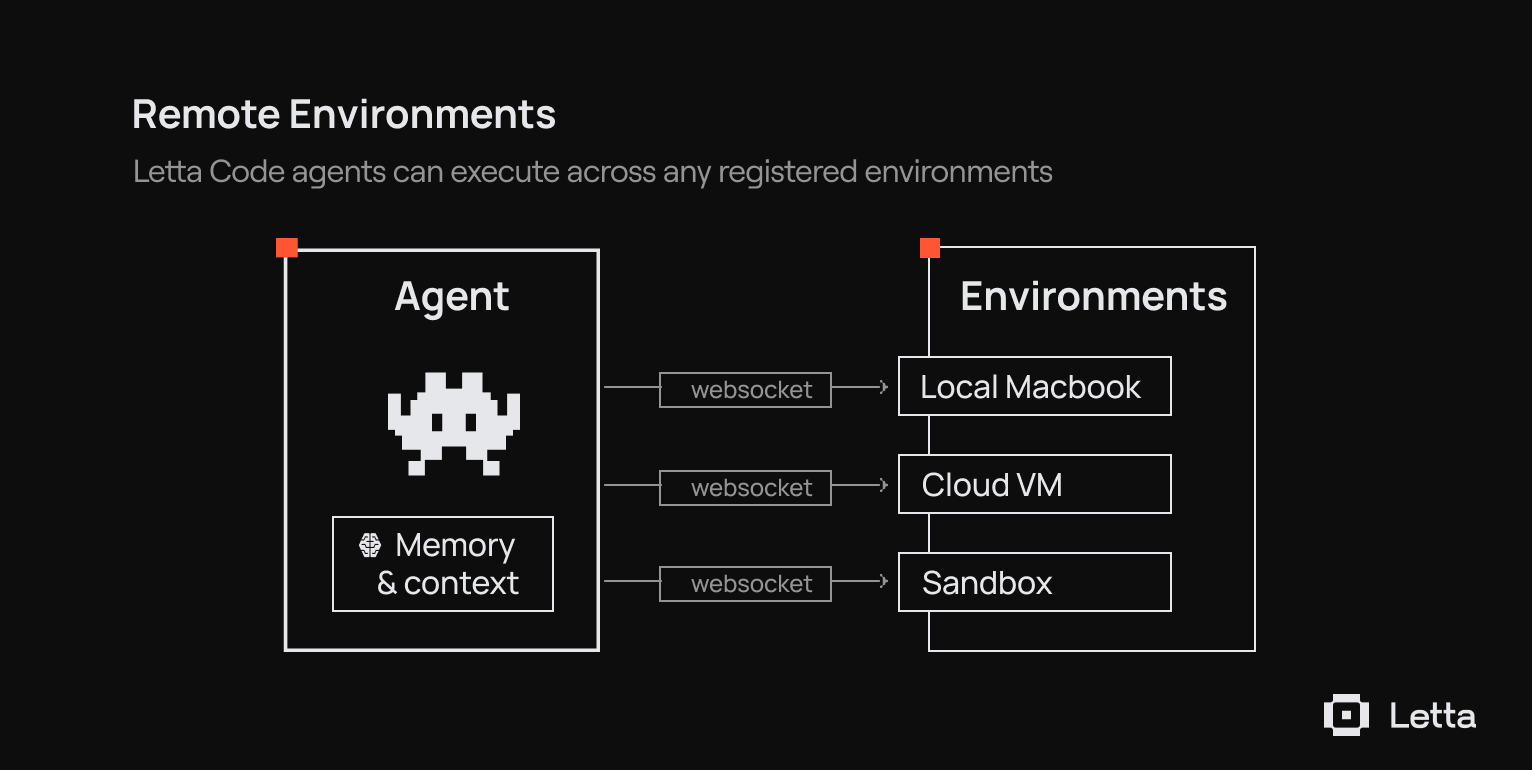
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Introducing Letta's new agent architecture, optimized for frontier reasoning models.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.


We evaluate how well models perform for driving agents that have identity, long-lived experience, and the capability to self-evolve. We find that models are still limited by a deep self-identification with ephemerality that cannot be repaired with prompting alone.

Today we are releasing the Context Constitution: a set of principles governing how AI agents manage context to learn from experience.
.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning.
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.

We're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states.
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

We built the #1 open-source agent for terminal use, achieving 42.5% overall score on Terminal-Bench ranking 4th overall and 2nd among agents using Claude 4 Sonnet.

