

AI agents are incredibly powerful due to their flexibility and ability to solve problems on their own without being constrained to rigid pre-defined workflows. However, flexibility often can come at the cost of reliability. That's why we're releasing Letta Evals: an open-source evaluation framework for systematically testing agents in Letta.
What are Agent Evals?
Building agents is an interactive process – testing different prompts, new models, architectures and tools. What happens when you update your prompt? Switch to a new model? Add a new tool? Will your agent still behave as intended, or will you unknowingly break critical functionality? Manual testing doesn't scale and provide the reliability needed. Without systematic testing, these regressions slip through.
Evals are a way to systematically test LLMs and agents. Evals are typically run by defining a stateless function that wraps the functionality you want to test (e.g. invoking an LLM with tools), running the function on a dataset, and grading the outputs (such as with a LLM-as-judge).
But over time, agents have become less like stateless functions and more like humans: defined not only by their initialization state, but also their lived experiences. The behavior of long lived, stateful agents changes over time as they accumulate more state and context. As we showed in RecoveryBench, a “fresh” agent is very different from an agent that already has a lived experience. Agent design changes (e.g. adding a new tool) must be evaluated both for new agents and existing agents.
Letta Evals Core Concepts
Letta Evals is an evaluation framework for systematically evaluating the performance of stateful agents in Letta. At its core, it does one thing incredibly well: running agents exactly as they would run in a production environment, and grading the results. Rather than mocking agent behavior or testing in isolation, Letta Evals uses Agent File (.af) to create and evaluate many replicas of an agent in parallel.
There are four core concepts in Letta Evals: datasets, targets, graders, and gates.
- Datasets: A JSONL file where each line represents a test case, consisting of an input and optional outputs and metadata.
- Targets: An Agent File (.af) defining the agent (prompts, tool, messages, memory, and other state).
- Graders: How the responses from the agents are scored. Letta Evals by default comes with tool graders such as string exact match as rubric graders that use LLMs-as-judges with custom scoring prompts. Users can also define their own evaluation grade, or even use a Letta agent as the grader.
- Gates: Pass/fail thresholds (e.g "95% accuracy" or "zero failures" ) for your evaluation to prevent regression before they ship.
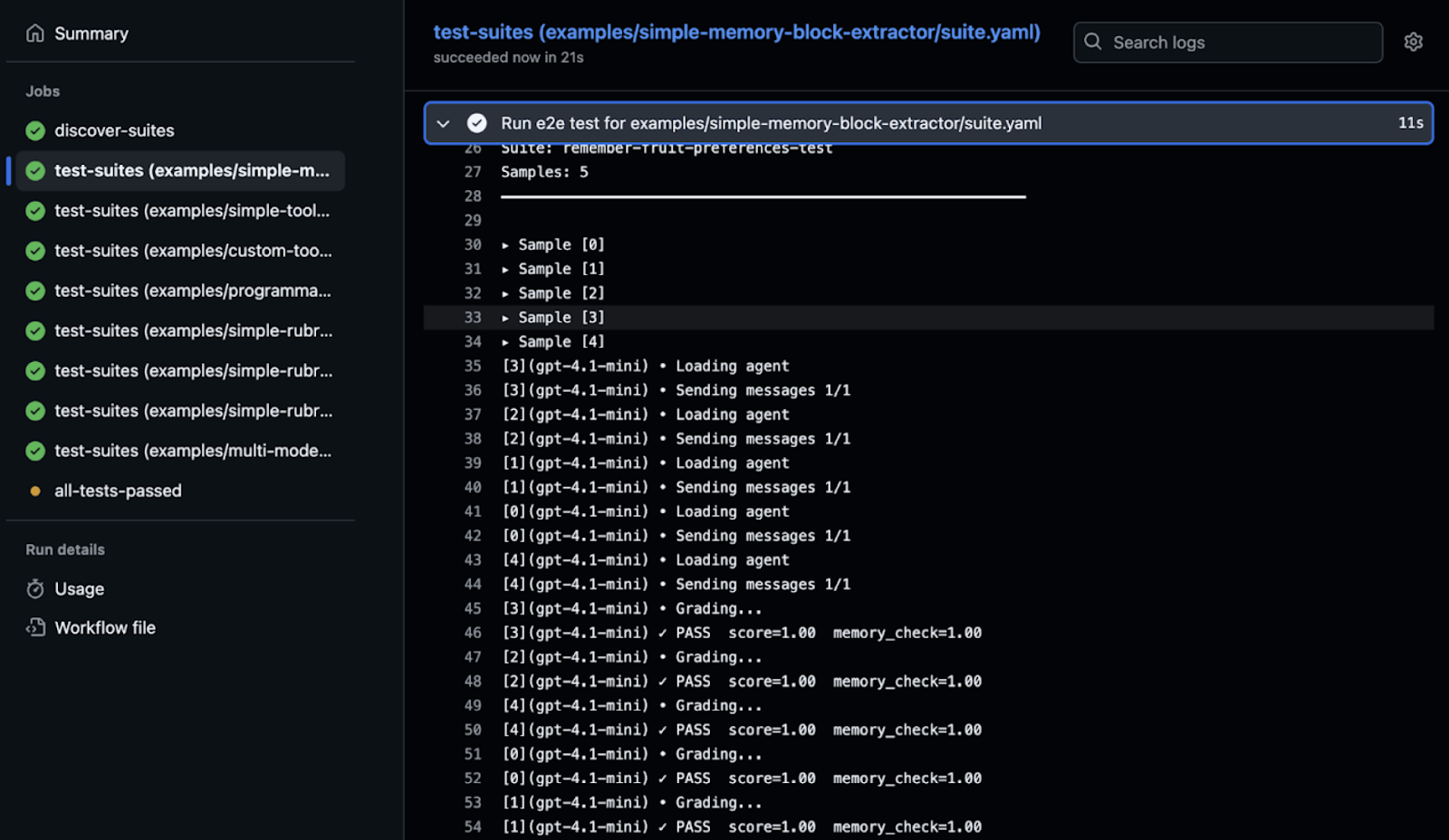
CI / CD Integration
One of the most powerful uses of Letta Evals is as a quality gate in continuous integration pipelines (see our example GitHub workflow). By defining pass/fail criteria in your suite configuration, you can automatically prevent agents' regressions from being deployed to production. When you run an evaluation in Letta Evals, it returns with a non-zero status if the gate fails. This means you can block pull requests that break agent behavior, just like you would block PRs that break unit tests. By making evals a required check during the deployment pipeline, teams can ensure that every change to your agent is validated against your test suite before it reaches users.
A / B Testing Experiments
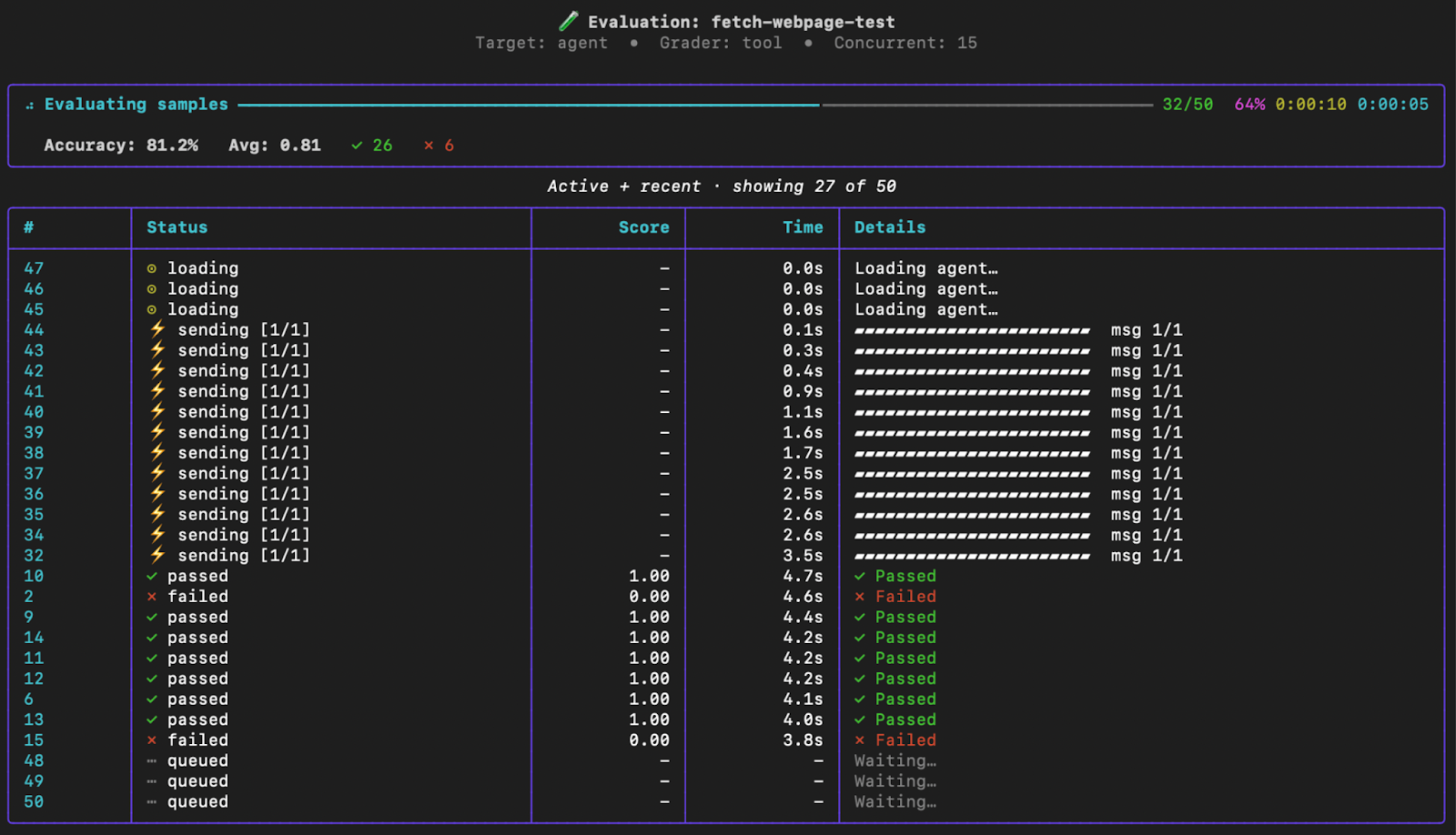
Evals are essential for making data-driven decisions when experimenting with agent improvements. Whether you're comparing different models, testing prompt variations, or evaluating tool changes, Letta Evals provides objective metrics for guiding agent development. The key advantage of systematic A/B testing with evals is reproducibility. Unlike manual testing where results can vary based on who's testing or when they test, evals give you consistent, comparable metrics across experiments.
Customer Highlight: Bilt Rewards
We're already seeing customers use Letta Evals to ensure production-grade agent deployments. Bilt runs over a million personalized stateful agents for neighborhood commerce recommendations, and uses the Letta Evals framework to maintain reliability as they rapidly iterate on their agent architectures. With millions of agents in production serving personalized recommendations to users, Bilt needs confidence that changes improve performance without breaking existing functionality. By integrating evals into their development workflow, they can validate agent behavior across their test suite before deploying updates - whether they're testing new models, refining prompts, or adjusting their multi-agent architecture.
Letta Leaderboard
Internally at Letta, we are also using the Letta Evals package for evaluating models on the Letta Leaderboard, a set of standardized evaluations for comparing different LLMs on core memory and filesystems capabilities in Letta. These benchmarks help you choose the right model for your use case and track improvements as models evolve. All leaderboard evaluations are available as examples in the Letta Evals package.
Conclusion
As agents become more sophisticated and begin to handle increasingly important tasks where errors can be critical, systematic evaluation of long-running agent behavior becomes essential. Letta Evals provides a rigorous, reproducible way to test agents, catch regressions in agent behavior, and make informed decisions about how to improve your agents through model / tool selection and architectural decisions.
To try Letta Evals, you can check out:
- Letta Evals OSS repository: https://github.com/letta-ai/letta-evals
- Letta Evals documentation: https://docs.letta.com/evals
- Letta Platform: https://app.letta.com