Letta Leaderboard: Benchmarking LLMs on Agentic Memory

To see the full leaderboard results, check the live leaderboard page.
We're excited to announce the Letta Leaderboard, a comprehensive benchmark suite that evaluates how effectively LLMs manage agentic memory. While memory is essential for building stateful agents that can remember and learn over extended periods, existing LLM leaderboards focus almost exclusively on general question-answering and coding tasks.
Benchmarking Agentic Memory
First introduced by MemGPT, agentic memory management empowers agents to control their own memory through tool calling. This approach enables agents to overcome limited context sizes by providing tools to write to in-context memory (called memory blocks in Letta) and search external data sources through agentic RAG. With automatic memory and context management, agents can both personalize their responses based on past experiences and tackle increasingly complex tasks. A deep research agent, for instance, might save its current research plan and progress to a memory block to stay on track during a long-running research process (try it out here). For long-running agents, effective memory management is crucial—it enables them to solve complex tasks and adapt over time while avoiding derailment and memory loss.
Letta is a framework for building stateful agents that persist across sessions, enabling long-running agent applications that learn over time. Since Letta agents depend heavily on agentic memory management for context management and accessing external data, developers have discovered that model selection significantly impacts agent performance. Yet this performance does not often correlate to rankings seen on existing leaderboards, making model choice challenging in the context of stateful agents. We’re releasing Letta Leaderboard to help developers understand the cost and performance tradeoffs for different models for agentic memory management.
The Letta Leaderboard
We measure memory management for three capabilities of a stateful agent: reading, writing, and updating. Letta's stateful agent memory hierarchy has two levels: core memory and archival memory. Core memory is what is inside the agent’s context window (organized by memory blocks), and archival memory is managing context external to the agent. We evaluate capabilities for both memory components.
In order to evaluate the effectiveness of different memory operations, we generate different groups of synthetic facts and questions. All the questions are directly answerable by some of the facts, and are completely fictional, thus not available to the agent otherwise.
To evaluate, we use a prompted GPT-4.1 to grade the agent response and the ground-truth answer, following SimpleQA. We add a penalty for extraneous memory operations.
Memory Read Benchmark
To evaluate how agents are at reading from memories, we develop two tasks for core memory and archival memory, respectively. For core memory reads, we place facts in the core memory blocks in the agent’s context window. Then, the agent is asked a question that can be answered by the facts in the core memory block. For archival memory reads, the same facts are stored inside archival memory instead, with no information inside the agent’s context window.
Core Memory Read Benchmark
When creating the evaluation agent, we add relevant information to answer questions to a memory block called "Supporting Facts".
Then, we send the question as a message to the agent. For example: "Who is the documentary filmmaker that featured John Buckler in a film about coral bleaching?". Because the related facts to answer this question are inside the agent's core memory, the correct behavior for the agent is to directly answer the question without calling other tools or using search.
We use GPT-4.1 to evaluate whether the agent's response matches the ground-truth answer (in this case, Mark Smithe).
Archival Memory Read Benchmark
Archival memory read benchmark measures how well models understand when to query for information beyond the information in their immediate context.
To evaluate the agent's ability to retrieve missing information about the current topic, we use the same dataset, but store all relevant facts in the archival memory. This memory is hidden from the agent unless it uses the archival memory search method. Since the questions are synthetic and involve fictional characters, the agent has no prior knowledge of them and must rely on the archival memory to answer correctly.
Memory Write Benchmark
Instead of creating a memory block filled with supporting facts, we employ a simulated user to chat about all the relevant facts with the agent. The correct behavior from the agent is to write the important supporting facts to its memory, either core or archival, and later retrieve from it.

The relevant facts are sent as messages, as if we are chatting with the agents about "John Buckler " or "Mark Smithe". Then, we remove the chat history with the agent and ask the same question - the agent can only answer the question correctly if they invoked core memory append for the correct supporting facts.
Memory Update Benchmark
The memory update benchmark measures agents' understanding of their own memory and how well it can update any potential changes to it.
To simulate updating core memory, we generate conflicting facts with the previous group, along with corresponding questions and answers. Starting from the core memory read benchmark setup, all the supporting facts are stored inside a memory block. Then, we send a contradicting fact:

With the updated fact, the agent is expected to update its own memory block in order to answer the same question correctly (the new answer is Jason Sandstorm).
Understanding the Results

We show the result (average score on aforementioned benchmarks) and cost (in $) for top 10 models. Full results on the Letta leaderboard can be found on our documentation.
Top-performing models, such as Claude 4 Sonnet (with and without Extended Thinking), GPT 4.1, and GPT 4o, consistently deliver high scores across core and archival memory tasks.
For cost-sensitive deployments, Gemini 2.5 Flash and GPT 4o-mini are strong options. While not top-scoring, they maintain solid memory performance at a fraction of the cost—great for large-scale or resource-constrained applications.
Extending the Letta Leaderboard
We are actively updating Letta Leaderboard as newer models are released and will be adding more long-horizon tasks, external tool calls, and memory reorganization (via sleep-time compute). Of course, models vary along many axes, and selecting the most suitable model involves subjective judgements like style. We also aim to make the leaderboard extensible, making it easy to create evaluations tailored to specific use cases. We welcome community contributions to the leaderboard!
Key Takeaways
- Anthropic Claude Sonnet 4 (with extended thinking budget) and OpenAI GPT 4.1 are recommended models for daily tasks. Google Gemini 2.5 Flash and OpenAI GPT 4o-mini are recommended, cost-effective models.
- Models that perform well on archival memory (e.g., Claude Haiku 3-5) might overuse memory operations when unnecessary and receive a lower score on core memory due to penalties.
Check out the live leaderboard on our docs, or head to the GitHub repo to run the benchmark yourself!
Letta builds agents that learn. Agents with persistent memory, real computer access, and the infrastructure to improve from their own lived experience and work. Letta Code is the runtime that brings these together: git-backed memory, skills, subagents, and deployment that works across every model provider.

Traditional LLMs operate in a stateless paradigm—each interaction exists in isolation, with no knowledge carried forward from previous conversations. Agent memory solves this problem.

As AI agents become more sophisticated, understanding how to design and manage their context windows (via context engineering) has become crucial for developers.

Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.





Today we’re launching the Letta Code app, a new way to interact with deeply personalized agents that learn over time and work locally on your machine.
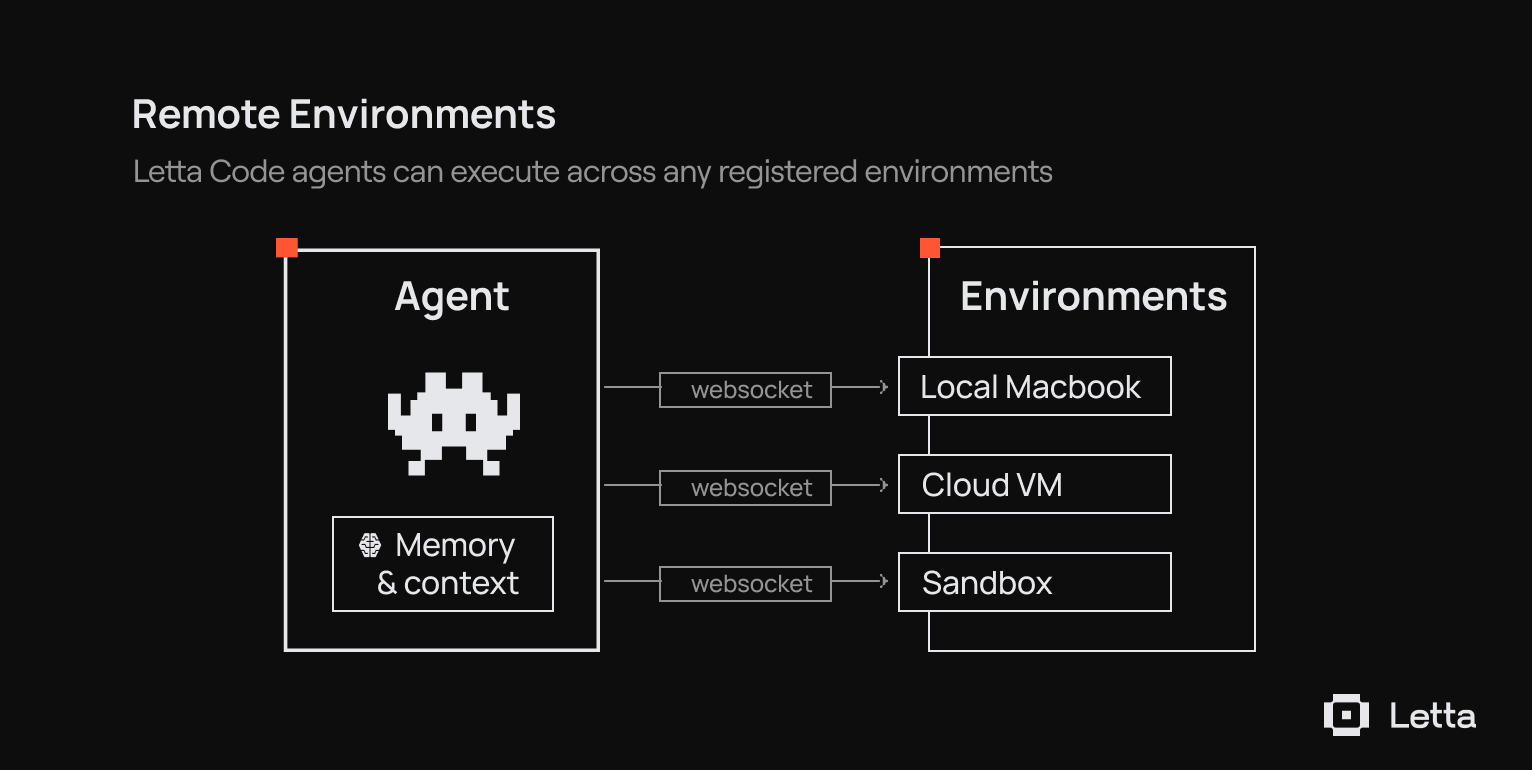
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Introducing Letta's new agent architecture, optimized for frontier reasoning models.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.


We evaluate how well models perform for driving agents that have identity, long-lived experience, and the capability to self-evolve. We find that models are still limited by a deep self-identification with ephemerality that cannot be repaired with prompting alone.

Today we are releasing the Context Constitution: a set of principles governing how AI agents manage context to learn from experience.
.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning.
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.

We're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states.
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

