Rearchitecting Letta’s Agent Loop: Lessons from ReAct, MemGPT, & Claude Code
A common definition for agents is that they're simply a loop that calls an LLM and executes a tool. In other words (as Simon Willison defines an agent):
An LLM agent runs tools in a loop to achieve a goal.
But not all loops are created equal. The underlying design of the agent loop fundamentally shapes how your agent behaves: when it decides to reason, when to terminate, and whether it gets stuck in infinite loops or exits prematurely.
What is agent architecture?
The performance of your agents depends not just on the model and prompts, but the agent architecture: exactly how the LLM is invoked in a loop to reason and take actions. At each iteration, the agent must decide to do one or more of the following:
- Call a tool (e.g., an MCP tool) or send a message
- Reason (spend compute cycles thinking)
- Terminate (exit the loop)
Each of these decisions can be controlled by the LLM itself (e.g. the LLM deciding to reason) or by the agent architecture controlling invocations to the LLM. Historically, LLMs could only specify tool calls or assistant messages explicitly, so additional logic from the agent architecture was necessary to trigger reasoning or make termination decisions. While modern LLMs often have reasoning capabilities built-in, they still lack a built-in way to determine whether to continue executing — this remains the responsibility of the agent architecture.
Early agent architectures: ReAct and MemGPT
ReAct: Sequential reasoning and actions
ReAct was an early and influential LLM-based agent that combined reasoning and actions in sequence to achieve tasks. In the ReAct architecture, the LLM would be prompted to generate (in each response) a thought, an action, and (optionally) a token indicating the loop should be terminated.

Since the ReAct architecture pre-dated tool calling and native reasoning in LLMs, generation of actions, thoughts, and stop tokens were all done through formatted prompts.
MemGPT: The first stateful agent
MemGPT was another early agent architecture and notably the first example of a stateful agent with persistent memory. MemGPT's architecture was built on top of early LLM tool calling, making every action a tool call (including assistant message, via a special send_message tool).
This design enabled the tool schemas to manage reasoning and control flow by injecting special keyword arguments into tools:
thinking: The model's reasoning or chain-of-thought (similar to “thoughts” in ReAct)request_heartbeat: Request tool chaining to continue execution
Each time the LLM invoked a tool, it would also be triggered to reason and determine whether the tool chain should continue. This allowed for agentic tool chaining and chain-of-thought reasoning before it was built into base models.
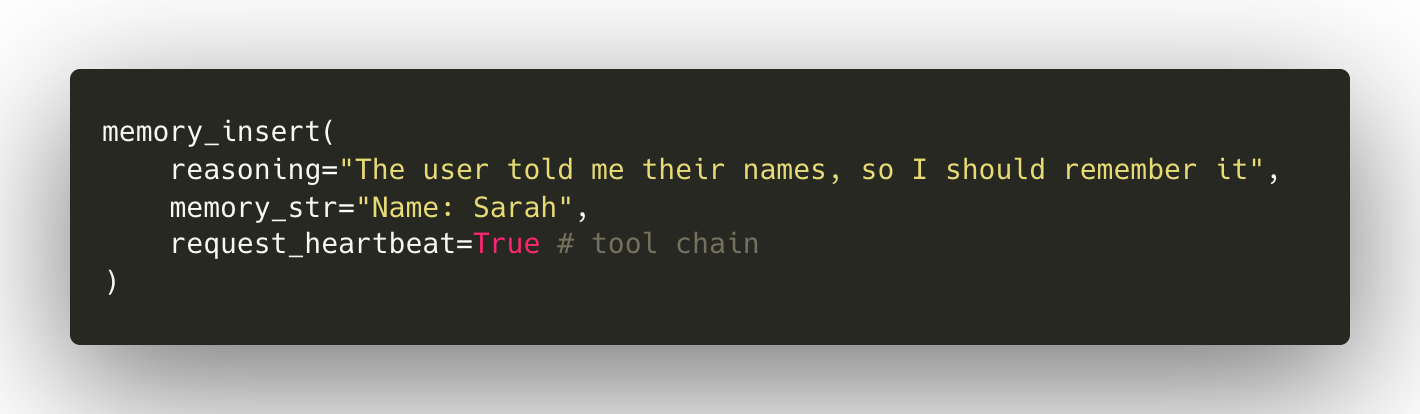
By default, request_heartbeat is set to False in MemGPT, so agents terminate by default rather than continue by default as in ReAct. The tool-based architecture also enabled powerful features to be built on top of the MemGPT agent loop such as tool rules, where tool calling patterns could be forced to follow specific constraints. However, MemGPT’s reliance on tool calling meant that only models that were capable of reliable tool-calling could work with MemGPT.
Although both ReAct and MemGPT are technically just “LLMs in a loop”, the way the underlying LLM is used differs significantly and results in different agent behaviors.
Agent architectures today: Letta, Claude Agents SDK, and OpenAI Codex
Agents are far more pervasive today than in 2023 when MemGPT was first released. Most models now support tool calling and native reasoning (reasoning tokens generated “directly” by the model rather than through prompting). LLM providers themselves now offer pre-built agents like OpenAI Codex and Claude Agents SDK, and have trained their models to be optimized to their own preferred agent architecture design choices.
Today's LLMs are also trained to be adept at agentic patterns such as multi-step tool calling, reasoning interleaved within tool calling, and self-directed termination conditions. As models become more heavily post-trained on new agentic patterns, agent architectures benefit from converging to match these patterns — in other words, staying "in-distribution" relative to the data the LLM was trained on.
Letta's new agent architecture
At Letta, we're transitioning from the previous MemGPT-style architecture to a new Letta V1 architecture (letta_v1_agent) that follows these modern patterns. In this architecture, heartbeats and the send_message tool are deprecated. Only native reasoning and direct assistant message generations from the models are supported.
What this means in practice
We’ve found the letta_v1_agent architecture significantly improves performance for the latest models like GPT-5 and Claude 4.5 Sonnet, with other benefits such as:
- Full support for native reasoning: The new architecture uses Responses API under the hood for OpenAI, and handles encrypted reasoning across providers. This allows models to fully leverage their reasoning capabilities to achieve frontier performance.
- Compatibility with any LLM: Tool calling support is no longer a requirement to connect an LLM to Letta.
- Simpler base system prompt: Understanding of the agentic control loop is baked into the underlying models.
At the same time, there are some downsides compared to the previous MemGPT architecture:
- No direct support for prompted reasoning: Non-reasoning models (e.g., GPT-5 mini, GPT-4o mini) will no longer generate reasoning, and developers cannot mutate the native reasoning state or pass reasoning traces across different models (from closed APIs that encrypt the reasoning).
- No heartbeats: Agents no longer understand the concept of heartbeats (unless implemented manually). For repeatedly triggering agents to run independently (e.g., processing time or sleep-time compute), you'll need custom prompting to explain this environment to the agent
- More limited tool rules: Tool rules cannot be applied to
AssistantMessage, as it is no longer a tool call.
The reasoning token dilemma
Reasoning is now built into models themselves, but the major frontier AI providers (OpenAI, Anthropic, Google Gemini) actively prevent developers from accessing and controlling this reasoning. One advantage of prompted reasoning tokens is ownership: you can see them, modify them, and send them to any model. In contrast, “native reasoning” tokens are often not transparent (the developer can only see a summary), and immutable (the developer is not allowed to modify them without voiding the API request). The performance difference between native reasoning and prompted reasoning remains unclear and likely varies by use case.
We'll continue supporting the original MemGPT agent architecture, but recommend using the new Letta V1 architecture for the latest reasoning models like GPT-5 and Claude 4.5 Sonnet.
Conclusion
Fully leveraging the underlying model capabilities to achieve frontier performance requires careful architecting of the underlying agentic loop and agent architecture, and adapting them alongside evolutions in model development. To see what agents are capable of today, try the latest agent architecture on the Letta Platform.
Letta builds agents that learn. Agents with persistent memory, real computer access, and the infrastructure to improve from their own lived experience and work. Letta Code is the runtime that brings these together: git-backed memory, skills, subagents, and deployment that works across every model provider.

Traditional LLMs operate in a stateless paradigm—each interaction exists in isolation, with no knowledge carried forward from previous conversations. Agent memory solves this problem.

As AI agents become more sophisticated, understanding how to design and manage their context windows (via context engineering) has become crucial for developers.

Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.





Today we’re launching the Letta Code app, a new way to interact with deeply personalized agents that learn over time and work locally on your machine.
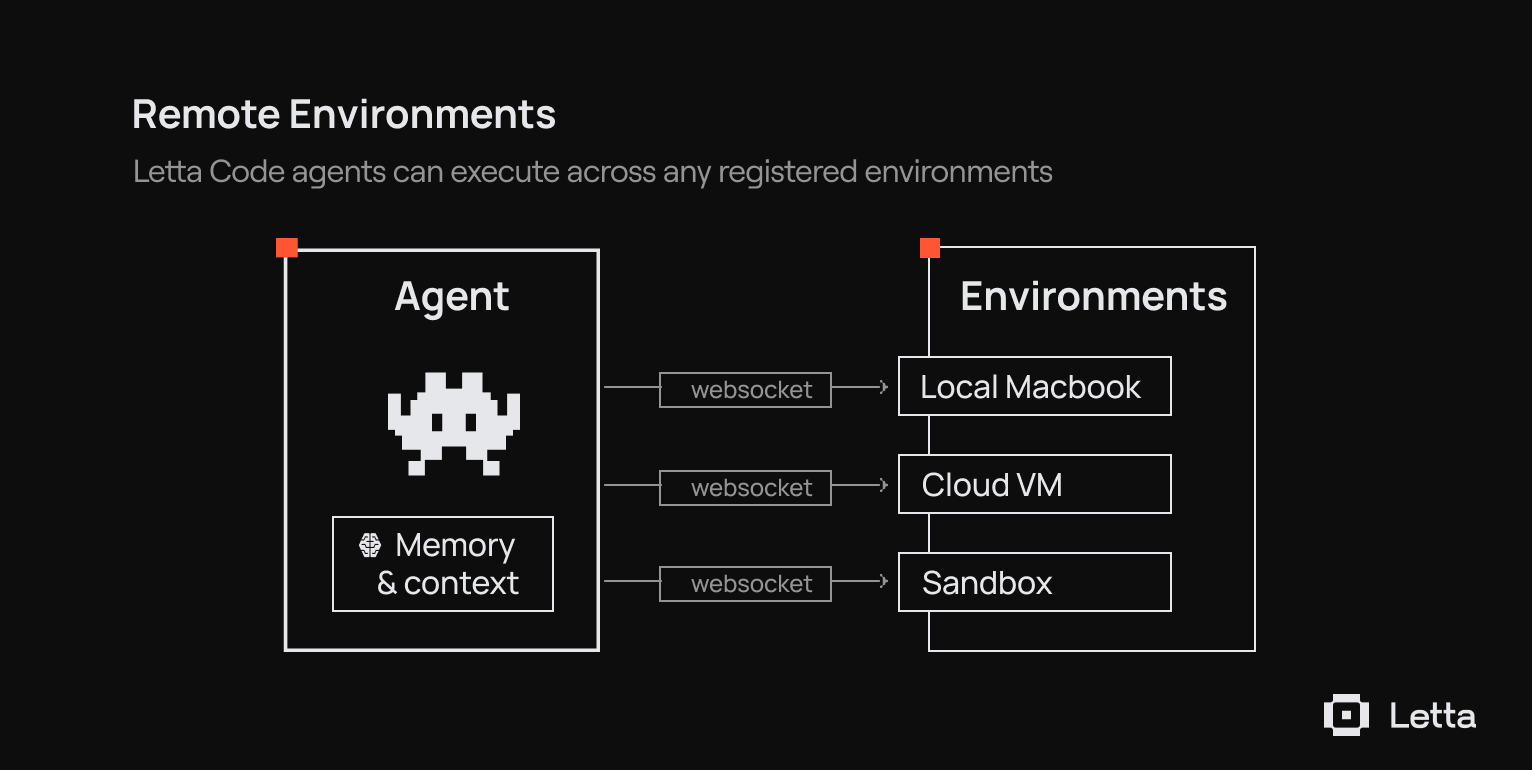
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.


We evaluate how well models perform for driving agents that have identity, long-lived experience, and the capability to self-evolve. We find that models are still limited by a deep self-identification with ephemerality that cannot be repaired with prompting alone.

Today we are releasing the Context Constitution: a set of principles governing how AI agents manage context to learn from experience.
.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning.
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.

We're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states.
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

We built the #1 open-source agent for terminal use, achieving 42.5% overall score on Terminal-Bench ranking 4th overall and 2nd among agents using Claude 4 Sonnet.

